
[论文学习]MM-EGO:迈向构建以自我为中心的多模态LLMS
资料
论文:[2410.07177] MM-Ego: Towards Building Egocentric Multimodal LLMs
简介
本文提出了一种面向第一人称视频理解的多模态基础模型——MM-EGO,旨在提升模型对长时第一人称视频的复杂理解能力。研究从数据、基准和模型设计三个方面展开:
- 开发了一个数据引擎,利用人类旁白自动生成700万条第一人称问答样本,构建了目前最大的第一人称问答数据集;
- 提出了EgoMemoria基准测试,包含629个视频和7026个问题,用于评估模型对视频细节的记忆和理解能力;
- 设计了MM-EGO模型,通过“记忆指针提示”机制,先对视频进行全局概览,再聚焦关键视觉信息以生成回答。
实验表明,MM-EGO在第一人称视频理解任务中表现出色,同时在去偏评估中展现出更强的真实理解能力。该研究为第一人称视频理解领域提供了重要的数据资源、评估标准和模型架构,推动了多模态大语言模型在该方向的发展。
“以自我为中心的QA”数据引擎
目前由于缺乏高质量的以自我为中心的QA对来训练具有以自我为中心的视频理解能力的MLLM。为了解决这一差距,我们开发了一个创新的“叙述到以自我为中心的QA”的数据引擎,该引擎可以根据Ego4D数据集中的人标注视频剪辑叙述自动生成与事件记忆相关的QA样本,而无需额外的手动注释。
数据引擎的工作流程如图所示。通过按正确的顺序组织连续的视频片段{剪辑1,剪辑2,…,剪辑N}及其相应的叙述{叙述1,叙述2,…,叙述N},我们创建了描述整个视频序列的综合叙述段落。然后,使用强大的纯文本语言模型,即GPT4-o,根据这些叙述段落生成与情节记忆相关的多样且自信的QA对。语言模型被指示附加每个QA对所基于的叙述句子的索引。这种索引允许我们将每个QA对映射回原始视频中的相应时间范围,从而提取出后续模型训练中至关重要的关键帧信息。
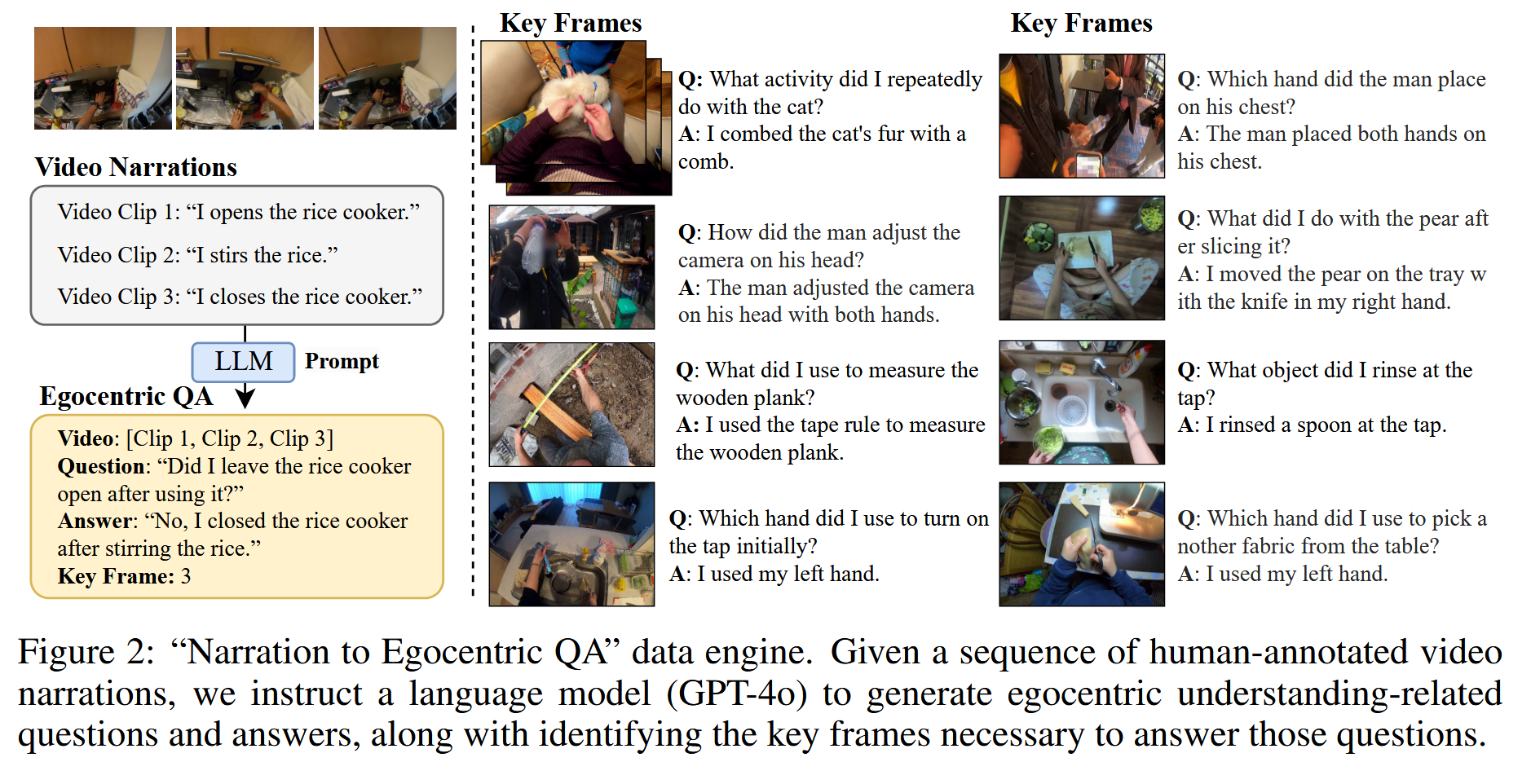
将这个数据引擎应用于广泛的Ego4D数据集,能够有效地扩展以自我为中心的QA数据的创建。我们根据官方的Ego4D情景记忆任务将数据集划分为训练集和测试集。自我中心的QA数据集在938k多轮对话中提供了超过700万个QA样本。
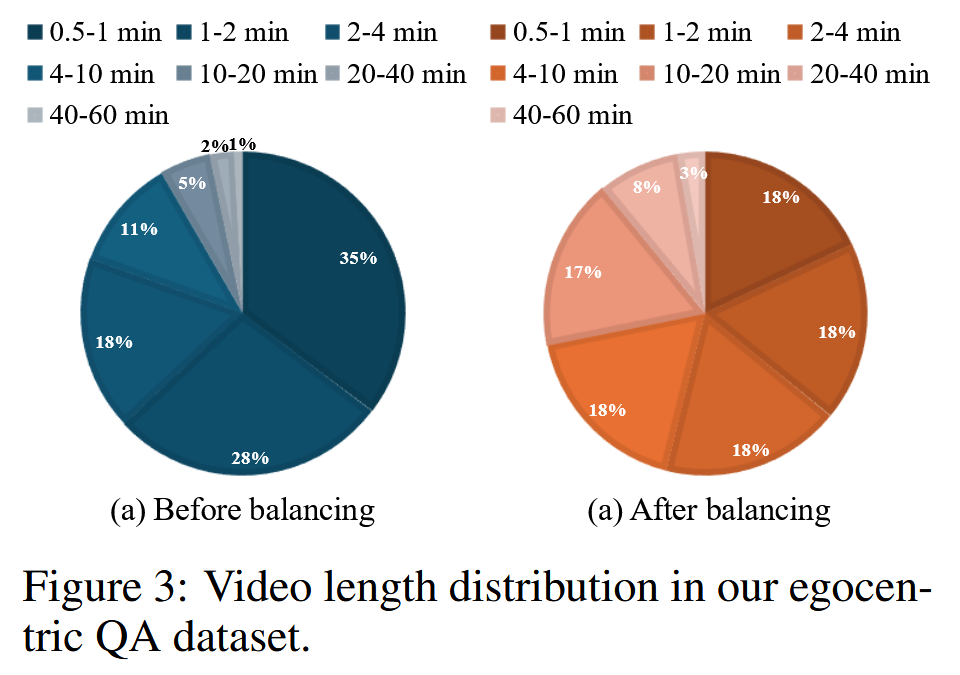
数据包含持续时间不同的视频,范围从30秒到1小时,如图所示。为了确保全面覆盖并防止偏向较短的视频,我们在训练中平衡不同视频长度之间的对话数量。这是第一个大规模的以自我为中心的QA数据集,其中包括持续时间范围如此延长的视频。
MM-EGO模型
文章目标是开发一个用于处理自我中心视频的MLM,这些视频冗长且视觉细节丰富。一方面,帧级信息对于捕获视频的完整内容是必要的,因为在采样期间跳过帧可能会导致视觉细节的显著损失。另一方面,处理由视觉编码器生成的所有视觉标记对于转换器模型来说在计算上是具有挑战性的。例如,如果每张图像被编码为729个视觉嵌入 (标记),那么一个300帧视频的视觉嵌入总数将为218,700个。然而,大多数MLLMs的训练上下文长度小于10,000令牌。
考虑到这些因素,文章引入了mm-ego模型,该模型用于处理大量以自我为中心的视频帧,同时在变压器主干网内保持可管理的计算成本。Mm-ego引入了一种创新的记忆指针提示机制,其操作分为两个主要步骤: global glimpse和fallback。
视觉和文本嵌入
给出一个输入视频和问题,第一步是将它们分别嵌入到视觉和文本嵌入层中,以便后续处理。首先将视频均匀采样到最多N帧,其中N可以在数百个范围内。
之后使用一个强大的视觉编码器SigLIP-so400m从这些帧中提取每帧的视觉特征图。按照先前的方法,应用一个2层的MLP来将视觉特征映射投影到LLM嵌入空间,并使用平均池将视觉特征映射的高度和宽度降低两倍并展平高度和宽度维度,导致N个相对高分辨率的视觉嵌入 {Vi ∈ RT × C,i ∈[1,N]},其中T是嵌入长度,C是嵌入维数。
对于文本嵌入,研究员使用Qwen2作为LLM,使用其分词器和嵌入层将输入文本转换为文本嵌入。对于问题q,我们将相应的文本问题嵌入表示为 {$\mathbf{E}_{\text{que}}^q \in \mathbb{R}^{T_q \times C}$,q ∈[1,Q]} 其中Q是问题的总数,$T_q$是问题q的嵌入长度。
记忆指针提示
因为使用LLM处理所有N个高分辨率视觉嵌入在计算上是困难的,建议以问题感知的方式识别关键视觉嵌入,并仅将这些选定的嵌入发送到后续的llm。
受以前关于指针网络工作的工作启发,研究人员提出了一种内存指针提示机制,如下图所示。
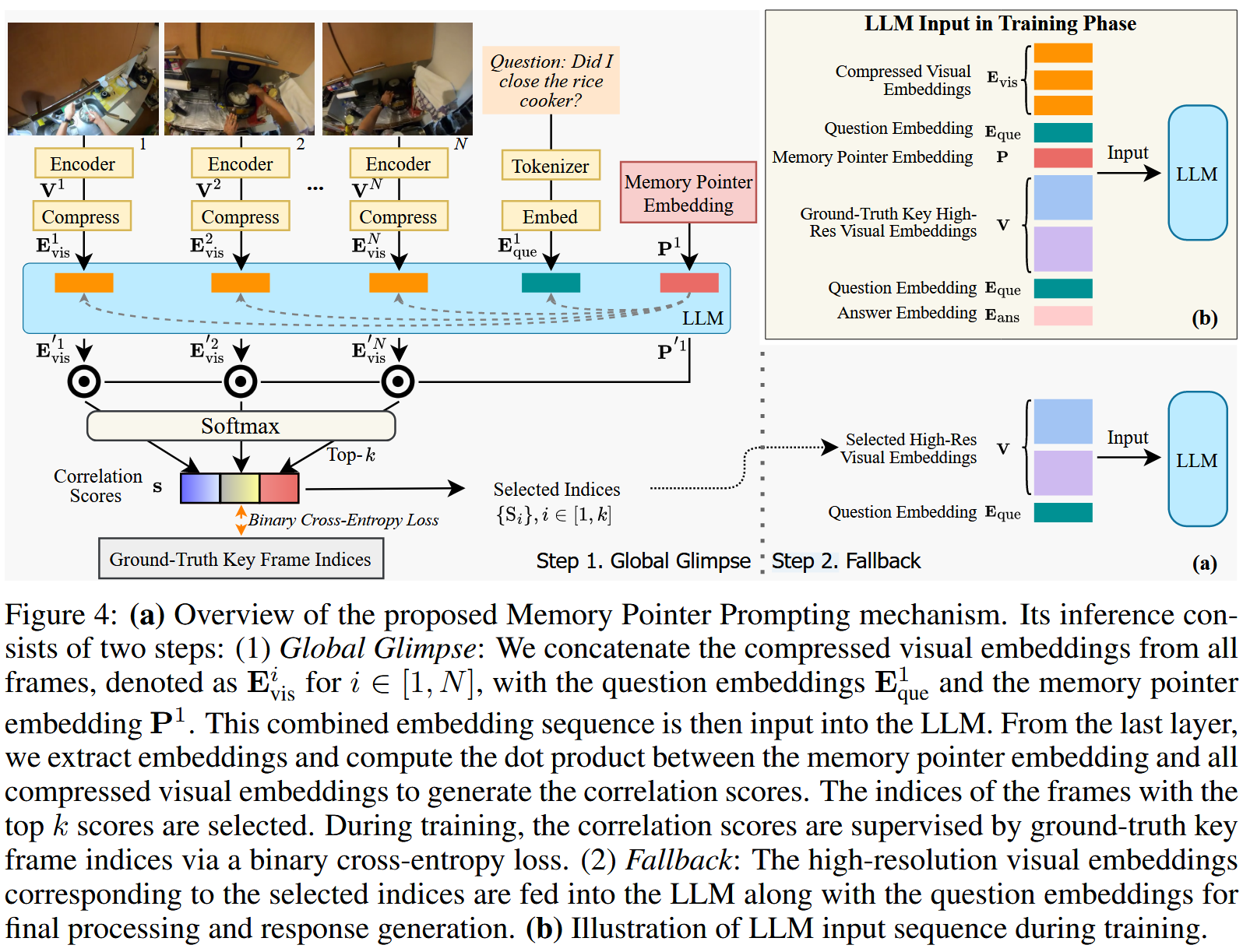
在推理过程中,内存指针提示包括两个步骤: Global Glimpse Step和Fallback Step.。在Global Glimpse Step步骤中,关键的视觉嵌入被从所有的框架级嵌入中识别出来,由问题的上下文引导。在随后的Fallback Step中,选择了重要的视觉嵌入,并将其更高分辨率的版本提供给LLM转换器骨干,以便进一步处理和生成语言响应。
Global Glimpse Step
首先通过沿嵌入长度维度的平均池化压缩视觉嵌入,得到一组压缩后的视觉嵌入{$\mathbf{E}_{\text{vsi}}^i \in \mathbb{R}^{1 \times C}$, i∈[1,N]}。接下来,我们引入一个可学习的记忆指针提示嵌入$P \in \mathbb{R}^{1 \times C}$,在这里,Q = 1,因为MLLMs一次只生成一个问题的答案。这样,问题嵌入后跟着一个指针嵌入,它将用于根据问题嵌入的知识识别关键视觉嵌入。然后整个嵌入序列被输入到LLM中,得到最终层的输出嵌入序列:
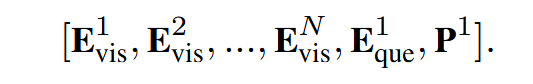
提取并堆叠处理过的视觉嵌入{$\mathbf{E}{\text{vsi}}^{‘i }\in \mathbb{R}^{1 \times C}$,i∈[1,N]}以获得矩阵$\mathbf{E}{\text{vsi}}^i \in \mathbb{R}^{N \times C}$。我们在$E_{vis}$和$P^{‘1}$之间进行softmax点积操作:
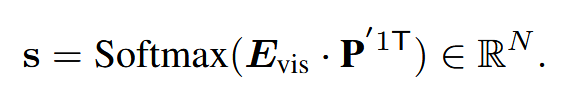
这里是一个相关性分数向量,表示问题与每个帧之间的相关性。
- 该步骤首先对视频的所有帧进行压缩,生成低分辨率的视觉嵌入。
- 模型使用一个可学习的“记忆指针”嵌入,结合问题文本的嵌入,来确定与当前问题最相关的关键帧。
- 具体做法是计算压缩视觉嵌入与记忆指针之间的相关性分数,从而选择与问题最相关的前 k 个关键帧。
Fallback Step
- 在选定的关键帧之后,系统提取它们的高分辨率视觉嵌入(high-resolution visual embeddings),并将其输入到大模型中进行进一步的语言推理和答案生成。
- 这一过程使得模型既能保持对整个视频的全局理解,又能针对特定问题聚焦于关键细节,提高回答的准确性。
Training Procedure
鉴于mm-ego的新颖设计,其训练过程与流行的MLLMs不同 。具体来说,让问题q ∈[1,Q] 的答案嵌入表示为$E_{ans}^q$,然后训练过程中的输入嵌入序列表示为:
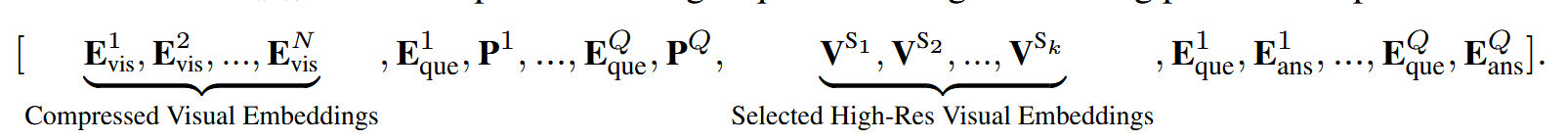
即输入序列的构建逻辑:
- 输入所有帧的 压缩视觉嵌入(N 个),这些嵌入可以帮助模型形成全局理解。
- 输入问题嵌入 和 记忆指针嵌入,用于指引模型关注关键视觉信息。
- 输入选定的关键帧的高分辨率视觉嵌入,即只传递与当前问题最相关的帧,以减少计算负担。
- 输入问题和答案嵌入,帮助模型进行语言推理,并通过 交叉熵损失 计算答案生成的准确性。
并且提供了图4中训练期间输入嵌入序列结构的简化图示 (其中Q = 1)。在这里,我们首先输入所有N帧的压缩视觉嵌入,然后是问题嵌入和内存指针嵌入。接下来,我们整合了k个选定的高分辨率视觉嵌入 (基于基本真实关键帧标签),最后整合了问题和答案嵌入。一旦输入序列如上所述准备好,我们就可以像传统的大型语言模型一样训练mm-ego。
训练流程
1、预训练初始化:
- MM-Ego 以 LLaVA-OV 7B 作为基础模型进行微调(fine-tuning)。
- 视觉编码器使用 SigLIP-so400M ViT 进行帧级视觉特征提取。
- 语言模型架构采用 Qwen2-7B。
2、数据输入:
- 处理 egocentric 视频,提取帧并进行视觉嵌入映射。
- 通过 记忆指针提示(Memory Pointer Prompting) 选取关键帧。
3、前向传播:
- Global Glimpse 计算关键帧相关性分数,并选出 Top-k 关键帧。
- Fallback使用高分辨率关键帧嵌入,结合文本信息输入 LLM,生成答案。
4、损失计算:
- 监督关键帧选择,优化二元交叉熵损失(BCE Loss)。
- 监督答案生成,优化语言交叉熵损失(Cross-Entropy Loss)。
5、参数优化:
- 反向传播计算梯度,并使用AdamW优化器进行权重更新。
6、测试与评估:
- 在EgoMemoria和其他基准测试上评估模型性能,分析语言偏差(language bias),计算去偏均值准确率(MDA, Mean Debiased Accuracy)。
实验
实验设置
实验数据
EGOMEMORIA基准测试:为了评估自我中心的MLLMs的表现,特别是在情节记忆能力方面,文章提出了一种新的基准叫做EgoMemoria。具体来说,我们从Ego4D数据集验证集中的人标注叙述中生成与记忆相关的问题和答案。
- 基于 Ego4D 数据集的验证集构建,确保数据质量。
- 采用 “叙述转 Egocentric QA” 数据引擎自动生成问题和答案。

训练模型
1、训练数据:
- Egocentric QA 数据集(自动生成)
- Ego4D Narration 数据集(Ego4D 的视频描述)
- LLaVA-NeXT SFT 数据(包括 AI2D, DocVQA, COCO, ScienceQA 等)
- ShareGPT4Video, ActivityNet-QA(用于多模态任务增强)
2、预训练模型
- 基础模型:LLaVA-OV 7B
- 视觉编码器:SigLip-so400M ViT
- 语言模型:Qwen2-7B
实验结果
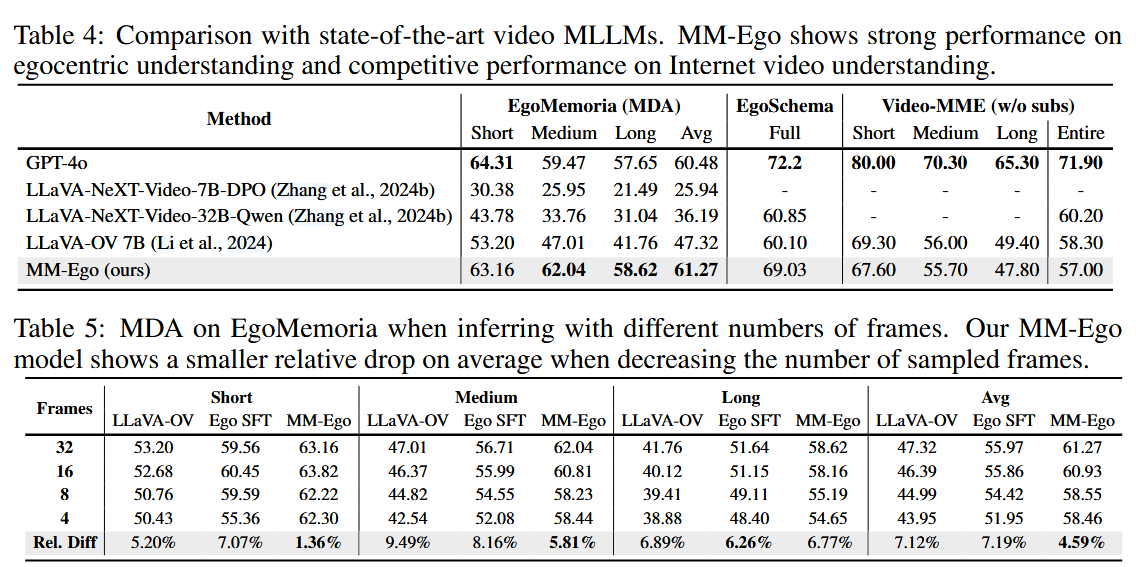
三种模型比较
- lllava-OV
- lllava-OV+使用论文的MM-Ego SFT数据混合 (称为 “Ego SFT”)
- lllava-OV+论文的MM-Ego模型进行微调版本
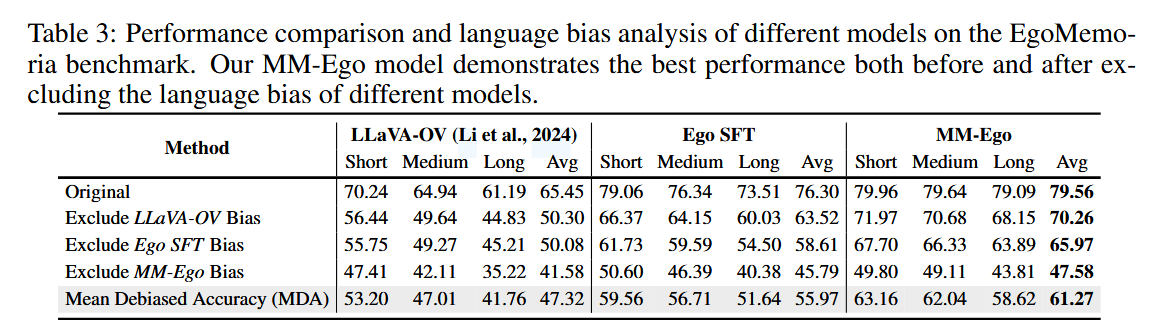
采样帧数影响(Table 5)
减少输入帧数(32 → 4)
- LLaVA-OV:下降 7.12%
- MM-Ego:仅下降 4.59%
- 说明 MM-Ego 关键帧选择更有效,即使采样帧数减少,性能下降较少。
关键帧选择可视化(Figure 6)
- 全局概览步骤(Global Glimpse) 可有效选出最相关的关键帧,提升模型回答的精准度。
- 示例问题:
- “我用哪只手拿起了锅?” → 模型成功选出关键帧,回答正确。
- “我把调味料如何加入锅里?” → 部分关键帧选取错误,导致回答错误。
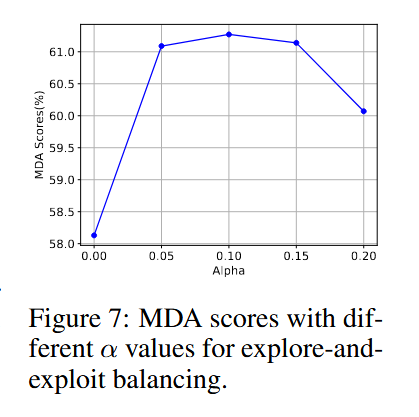
探索-利用平衡参数(Figure 7)
不同 α 值的影响
- 设定 α=0.1\alpha = 0.1α=0.1 时,模型性能最佳。
- 说明适度的探索机制有助于提高模型对未知情况的适应能力。
真实世界示例(Figure 8)
测试一个 2 分钟的 egocentric 佩戴式摄像机视频
用户问题:
- “我把钱包放在哪里?” → MM-Ego:在桌子上(正确)
- “我看到什么可以玩的东西?” → MM-Ego:一个吉他(正确)**
说明 MM-Ego 具备现实应用价值。

总结
本论文提出了 MM-Ego,一种专为 Egocentric(自我中心)视频理解 设计的MLLM,并在数据、基准测试、模型架构 方面做出重要贡献。研究者构建了 700 万条 Egocentric QA 数据集,提出 EgoMemoria 基准测试 以评估模型的 情景记忆能力,并引入去偏均值准确率(MDA) 以消除语言偏差影响。同时,创新性地提出 Memory Pointer Prompting 机制,通过 “全局概览 + 关键帧回退” 方法高效筛选视频关键信息,提升长时视频理解能力。
实验结果表明,MM-Ego 在 EgoMemoria 上超越所有基线模型,去偏准确率(MDA)达 61.27%,且即使减少输入帧数仍能保持较高性能,证明其在 Egocentric 任务** 上的高效性与鲁棒性。MM-Ego 的研究填补了 Egocentric MLLMs 领域的空白,为 AR/VR、可穿戴设备、机器人感知 等应用场景提供了有力的技术支撑。
