
[论文学习]SpatialCoT:基于坐标对齐和思想链的具身任务规划
资料
简介
文章提出了一种名为SpatialCoT的方法,旨在通过空间坐标对齐和思维链CoT推理来显著提升VLMs的空间推理能力,从而更好地完成复杂的具身任务规划。论文指出,尽管现有的VLMs在语言和视觉理解方面取得了显著进展,但它们在处理复杂空间关系和生成精细动作时仍存在局限性。SpatialCoT通过两个核心阶段——空间坐标双向对齐和思维链空间锚定——解决了这一问题。该方法不仅在模拟环境中表现出色,还在真实世界任务中展现了强大的适应性。通过实验验证,SpatialCoT在导航和操作任务上均取得了优于现有最先进方法的结果,为具身AI领域的发展提供了新的思路和解决方案。
其方法分为两步:
相关工作
空间推理
- 空间推理是视觉语言模型(VLMs)的关键能力之一,已被纳入多个视觉问答(VQA)基准测试中。
- 大多数VLMs主要在仅包含2D图像和文本的数据集上进行训练,这些数据集缺乏足够的空间信息,从而限制了它们的空间推理能力。
- 为了增强VLMs的空间推理能力,一些研究工作如SpatialVLM和SpatialRGPT通过收集与空间相关的问题-答案数据并对其进行微调来实现这一目标。
- 近期工作如RoboPoint和RoboSpatial通过引入基于点的动作空间来生成更细粒度的动作,例如根据语言指令预测空间可用性。
具身思维链(Embodied Chain-of-Thought)
- CoT及其扩展已成为大型语言模型(LLMs)和视觉语言模型(VLMs)增强问题解决能力的关键技术。
- 这种技术已被用于解决复杂的具身任务,例如Inner-Monologue和CaP模型,这些模型通过环境反馈创建“内心独白”或模拟模型的思考过程来帮助规划。
- 现有研究主要关注语言基础(即粗粒度)的规划,论文认为这种思维过程也可以用于细粒度的空间推理。
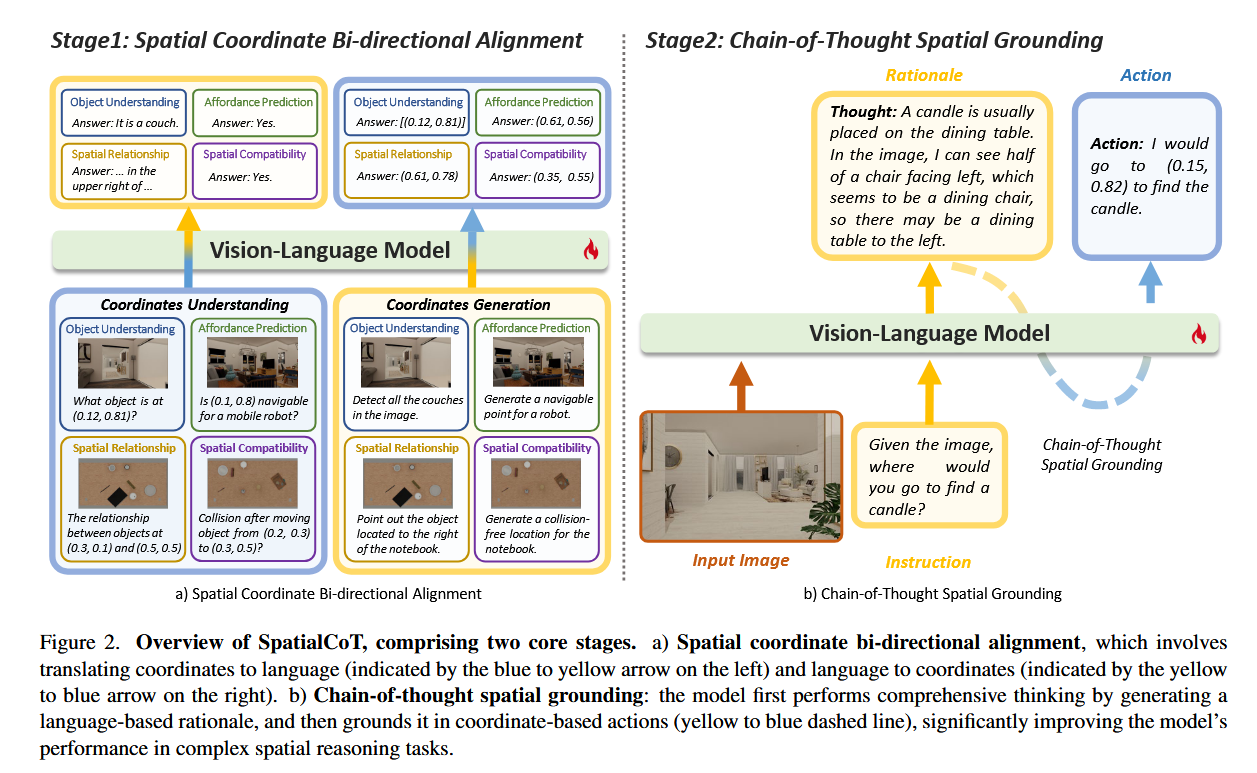
空间坐标双向对齐
之前的研究试图利用其他VQA数据,例如对象引用作为协同训练数据。而这些工作中的数据组织通常缺乏,其增强模型空间推理能力的潜力仍未得到充分利用。
所以在本文中,提出了视觉语言数据与坐标的显式对齐,这将显著帮助模型理解和生成基于坐标的输入和输出。即目标是使视觉语言模型能够理解和生成坐标。
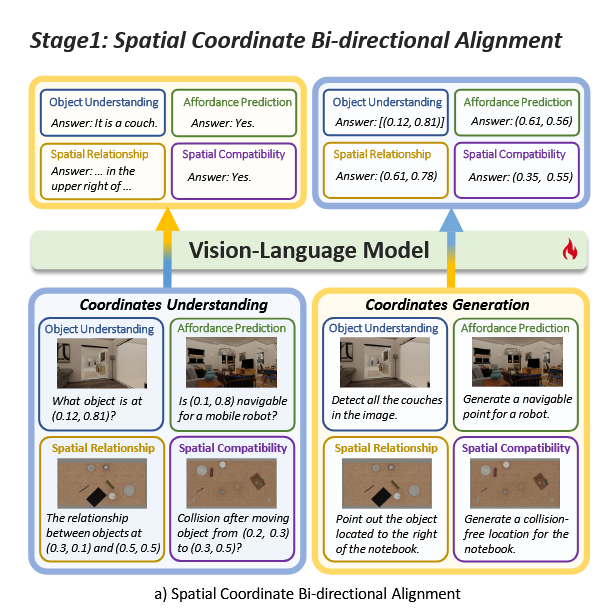
论文引入了双向对齐框架来强化这一过程。具体来说,模型需要处理两种类型的数据:
- 坐标理解(Coordinates Understanding):给定一个图像和一个包含坐标的文本指令,模型应输出关于指令中描述坐标的相应信息。例如,识别图像中特定坐标位置的对象。、
- 坐标生成(Coordinates Generation):给定一个图像和一个不包含坐标的纯文本指令,模型应生成一个或多个坐标来指出指令中描述的位置或区域。
并且为了实现更全面的对齐,论文引入了多种类型的数据,这些数据可以分为四类:
- 对象理解(Object Understanding):匹配自然语言描述与图像中的具体视觉内容,即视觉定位。目标是根据给定的文本描述识别和定位图像中的对象。
- 可用性预测(Affordance Prediction):识别和预测对象或环境允许的可能动作。例如,确定机器人可以无碰撞地导航的区域,或理解如何抓取或操作某些对象。
- 空间关系(Spatial Relationship):理解基于环境布局的对象之间的关系。
- 空间兼容性(Spatial Compatibility):增强模型理解和预测对象之间兼容性的能力。
空间定位思维链
该阶段的目标是利用VLMs的自然语言处理能力,通过生成理由(rationale)来指导空间推理任务。
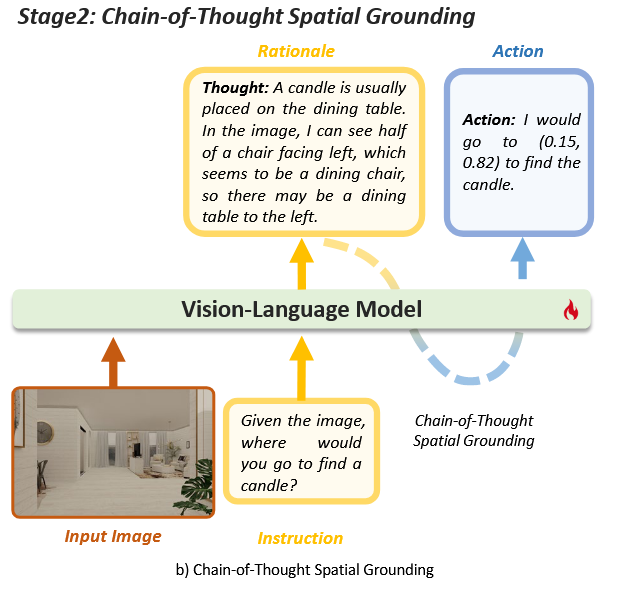
通过这种方式,模型能够在复杂的任务中进行更细致的推理,并将其转化为基于坐标的动作。
- 理由生成(Rationale):模型首先生成一个理由,即对任务的思考过程。在这个过程中,模型利用其空间和常识推理能力来提供完成任务所需的指导。
- 动作生成(Action):基于生成的合理理由,模型生成适当的坐标动作。通过在前一阶段中对齐语言和坐标,理由(用语言表达)可以有效地转化为坐标,而无需大量的微调数据。
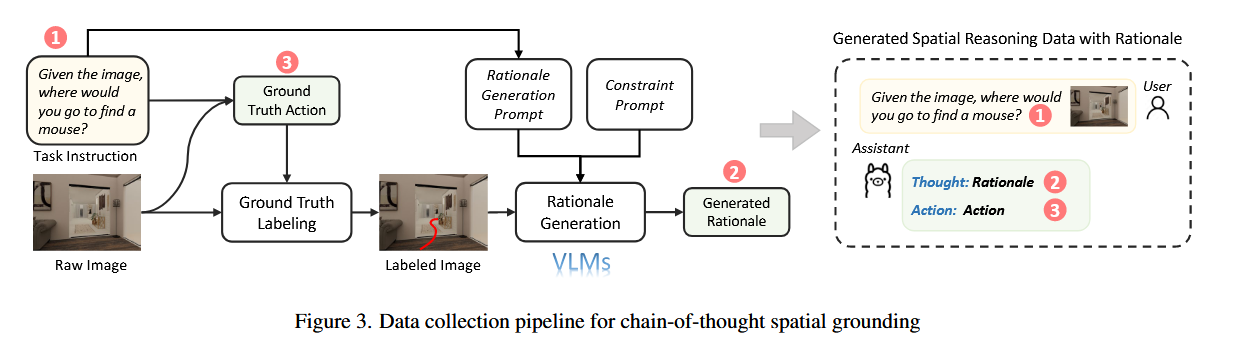
为了高效地收集高质量的推理-动作数据对,设计了自动化的数据生成流程:
- 初始动作获取:首先,从模拟器中以规则化的方式获取真实动作,确保动作的优化性。
- 图像标注:将真实动作标注在输入图像上,可以是轨迹或子目标点,具体取决于任务。
- 理由生成:使用强大的视觉语言模型根据动作标注的图像和任务指令生成理由。为了避免信息泄露,引入了一个额外的约束提示,确保生成的理由不包含真实动作的信息。
实验
实验设置
实验任务
导航任务
- 对象目标导航:不同于以往研究中将导航任务视为区域定位问题(即模型只需生成当前视图中的位置),采用更具挑战性的对象目标导航任务。在这种任务中,智能体必须找到当前视野之外的目标对象。模型被要求在每个观察中生成最佳子目标点,以便尽快定位目标对象。
- 复杂性因素:导航任务的复杂性考虑了状态(如遮挡)、目标(如目标数量和空间约束)、动作(如动作格式和所需技能的数量)以及环境转换(如动态不确定性)等因素。
操作任务
- 桌面重排:论文使用桌面重排任务作为操作任务的评估标准。这是一个比RoboPoint中的Where2Place任务更具挑战性的扩展。给定一个用语言指令描述的目标布局,模型需要逐步移动物体,通过生成每个物体的起始和结束位置,直到达到期望的布局。
- 复杂性因素:操作任务的复杂性考虑了物理概念(如碰撞)和人类常识(如何时停止)的理解,以及长视域规划能力的需求。
实验模型
- 专门的空间推理模型Robo-Point
- 开源的LLaMA3.2V等VLM
- 封闭源的GPT-4o等VLM
- Llama3.2-Vision 11B作为视觉语言模型的骨干。在两个阶段中,我们都使用LoRA对收集的数据集进行微调。每个阶段的训练过程跨越了2个周期。
实验结果
针对性的回答了四个问题:
- a)两阶段训练过程是否能有效提高视觉语言模型的空间推理能力?
- b)哪种类型的具身规划任务最受益于Spatial-CoT的改进?
- c)VLM的基本能力和它们在具身规划任务中的下游性能之间是否存在正相关性?
- d)思维链如何有助于提高VLM的空间推理能力?
问题A
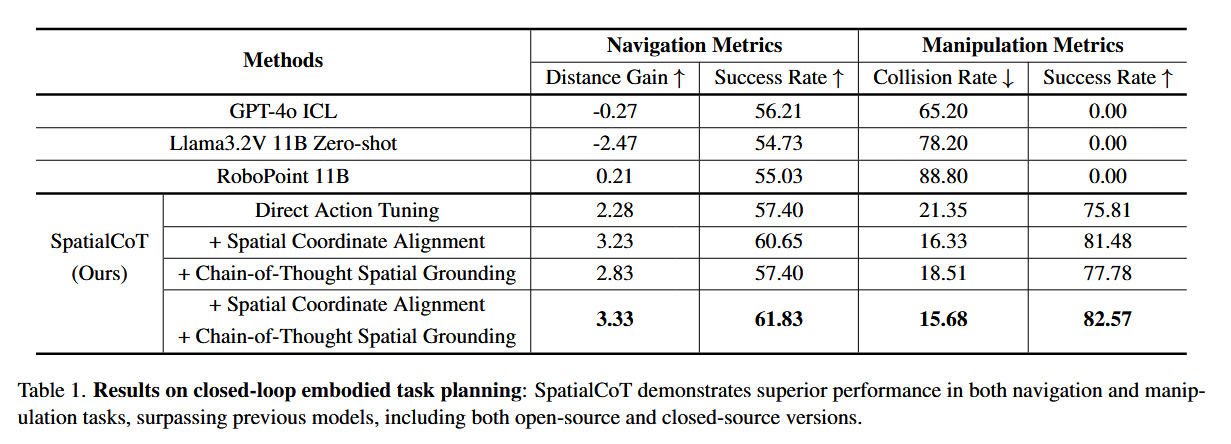
通过将SpatialCoT与基线模型在导航和操作任务上进行比较,验证了两阶段训练过程的效果。
- 在导航任务中,使用距离增益(DG)和成功率(SR)作为指标。结果显示,GPT-4o ICL和LLama3.2V 11B Zero-shot的表现较差,而RoboPoint的表现稍好。直接动作调优的基线方法提高了DG到2.28,结合空间坐标双向对齐后提高到3.23,引入链式推理后提高到2.83,两者结合提高到3.33,显示出显著提升。
- 在操作任务中,碰撞率(CR)和成功率(SR)是评估指标。直接动作调优显著降低了碰撞率到21.3%,成功率提高到75.8%。SpatialCoT进一步提高了这些指标,碰撞率为15.6%,成功率为82.6%。
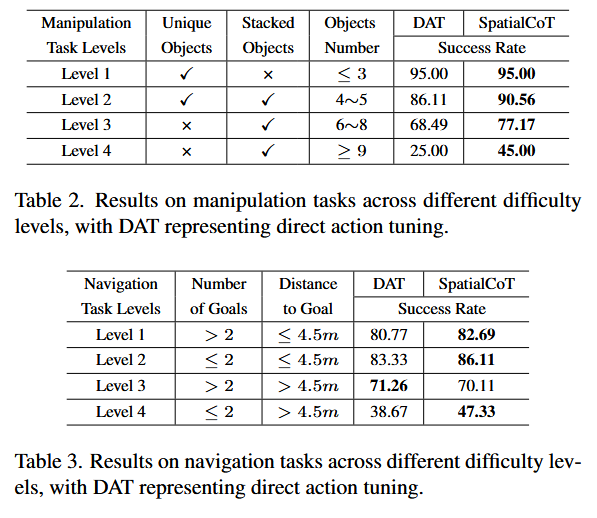
问题B
通过将任务按难度级别分类,分析结果表明,操作任务中大多数失败来自于非唯一对象和高数量对象的情况。SpatialCoT在这些任务中表现出显著改进,成功率分别提高了8.68%和20.00%。
在导航任务中,SpatialCoT在所有难度级别上都表现出色,尤其是在最具有挑战性的级别(目标较少且距离较远)上,成功率提高了8.66%。
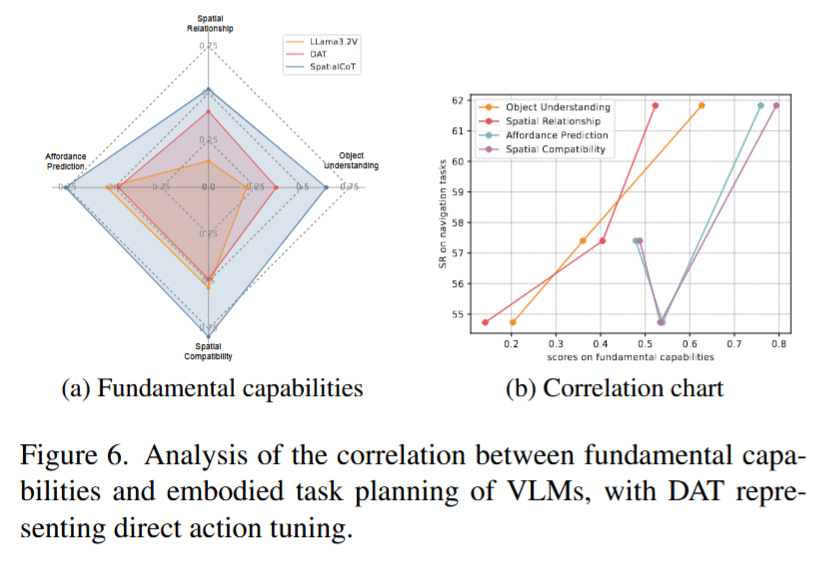
问题C
评估结果表明,SpatialCoT在所有基本能力类别中均优于其他模型。
通过分析每个基本能力类别与下游性能之间的相关性,发现对象理解和空间关系之间存在明显的正相关关系,表明基本能力与下游任务性能之间存在正相关。
问题D
- 实验结果显示,链式推理过程显著增强了模型利用空间和上下文信息的能力,如房间布局和常识知识,以得出正确答案。
- 通过案例研究展示,SpatialCoT模型能够更好地考虑典型位置和当前布局,从而产生更准确的结果,而基线模型则生成了混乱的结果。

限制
SpatialCoT采用基于坐标的动作进行具身任务规划;然而,它没有考虑旋转等复杂的操作,使得它无法管理需要对象旋转的任务。此外,SpatialCoT作为一种视觉语言模型,依赖于2D图像进行视觉输入,因此需要未来的研究来探索3D输入的潜力,特别是在大空间中。
总结
本文提出了一种名为SpatialCoT的新方法,旨在通过空间坐标对齐和CoT推理显著提升VLMs在具身任务规划中的空间推理能力。该方法包含两个阶段:空间坐标双向对齐,使模型能够更好地理解和生成坐标信息;以及思维链空间锚定,利用VLMs的语言推理能力生成精细动作。实验表明,SpatialCoT在导航和操作任务中均优于现有方法,展现出强大的复杂任务处理能力。

