
[论文学习]LLMs的心灵之眼:大型语言模型中思维诱导空间推理的可视化
资料
简介
2024年的NeurIPS会议
论文提出了一种名为“Visualization-of-Thought(VoT)”的提示方法,旨在通过可视化大型语言模型(LLMs)的推理过程来激发其空间推理能力。人类在进行空间推理时,能够通过“心灵之眼”(Mind’s Eye)创建心理图像来增强空间意识并辅助决策。受此启发,作者设计了VoT方法,让LLMs在每一步推理后生成内部状态的可视化,从而引导后续推理步骤。研究选择了自然语言导航、视觉导航和视觉拼图三项任务进行实验,结果表明,VoT显著提升了LLMs的空间推理能力,甚至在某些任务中超越了现有的多模态LLMs。此外,论文还从认知角度探讨了LLMs生成心理图像的潜在机制,并分析了其在不同任务中的表现和局限性。
空间推理
空间推理是指理解并推断物体之间的空间关系、它们的运动以及与环境的交互的能力。这些领域需要基于视觉感知进行行动规划,并对空间维度有具体的了解。
为了评估LLM的空间意识和空间推理能力,该选择了测试导航和几何推理技能的任务,包括自然语言导航、视觉导航和视觉拼图。
自然语言导航
自然语言导航任务是基于先前研究人类认知,为参与者提供从图结构中采样的顺序转换。
在这种情况下,一个正方形地图由每个位置的随机行走指令和关联对象序列定义,并用W = {(l1, o1),(l2, o2)… (ln, on)}表示。给定一个正方形地图W以及导航指令序列I={i1,…,ik},模型的任务是识别指定位置l上的关联对象o∈W,该位置是由导航指令确定的。

视觉导航
视觉导航任务向LLM呈现一个合成的二维网格世界,挑战它使用视觉线索进行导航。模型必须生成导航指令以在四个方向(左、右、上、下)移动,从起点到达目的地的同时避开障碍物。这涉及两个子任务:路线规划和下一步预测,需要多跳空间推理,而前者更加复杂。
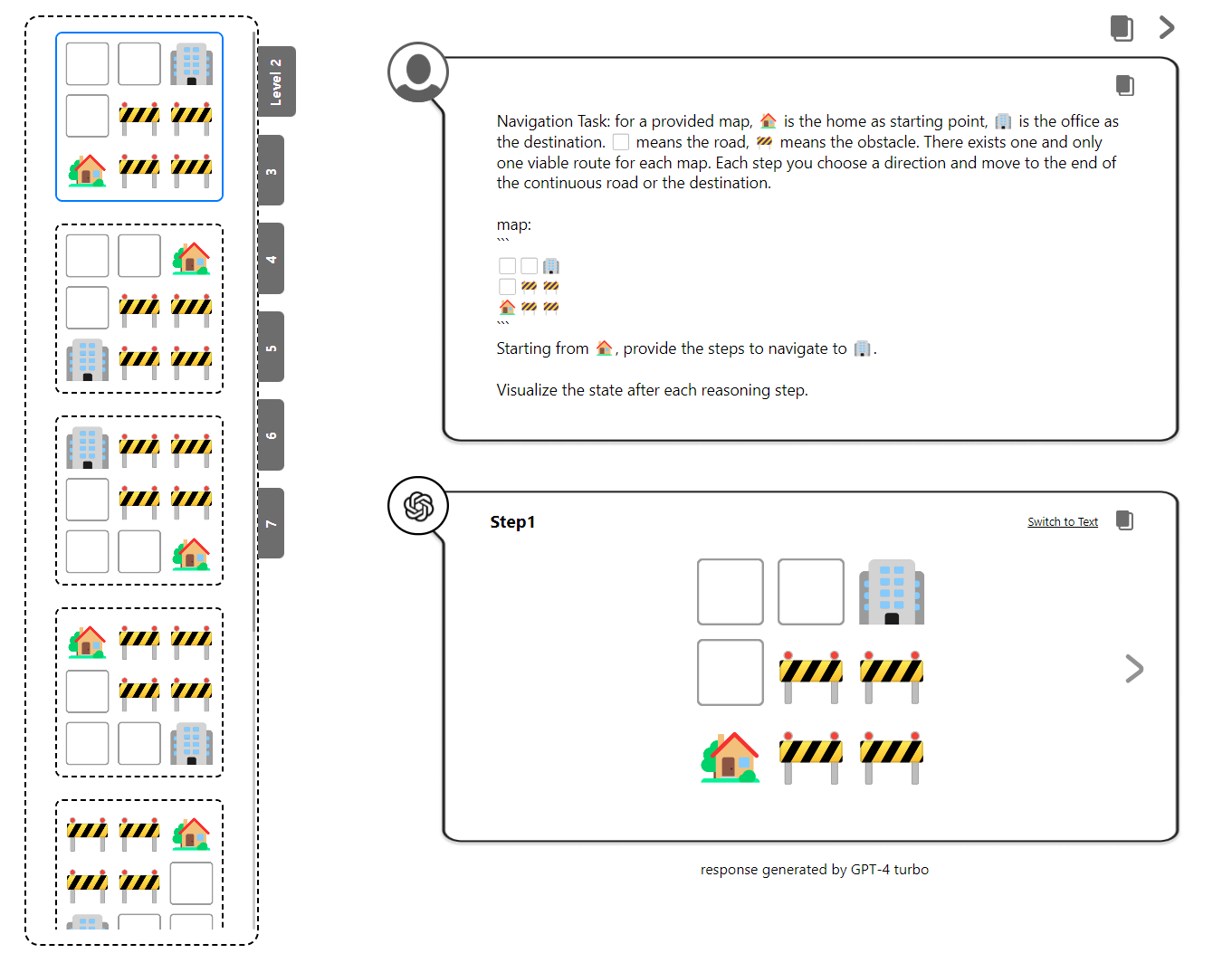
视觉拼图
多面体镶嵌是一种经典的空间推理挑战。文章扩展了这一概念来测试LLM理解、组织和在受限区域进行形状推理的能力,从而增强了对空间推理技能的评估。如图所示,任务涉及一个未填充单元格的矩形以及各种多面体块,例如四个正方形排列而成的I型四宫格。模型必须选择合适的多面体变种,比如选择I型四宫格的方向,以解决QA谜题。
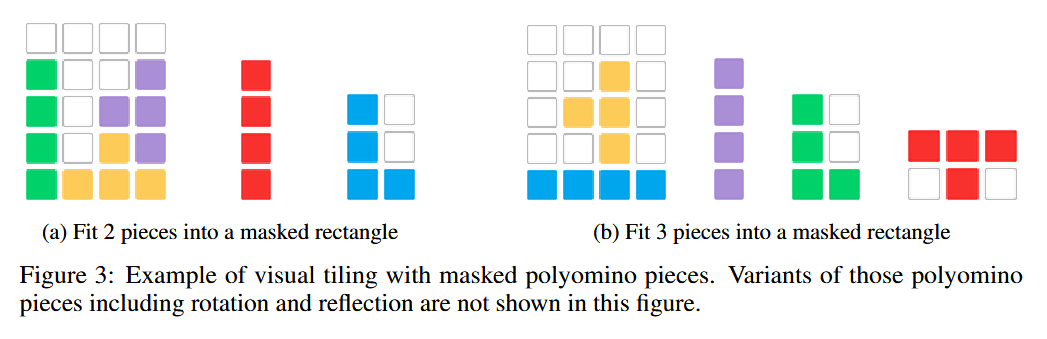
1 | Task: given a set of polyominoes and corresponding variations of each polyomino, fit them into the empty squares (⬜) in the target rectangle without overlapping any existing polyominoes or going outside the rectangle. The variations allow only translation, not rotation or reflection. It's guaranteed that there always exists a solution. |
Visualization-of-Thought(VoT)
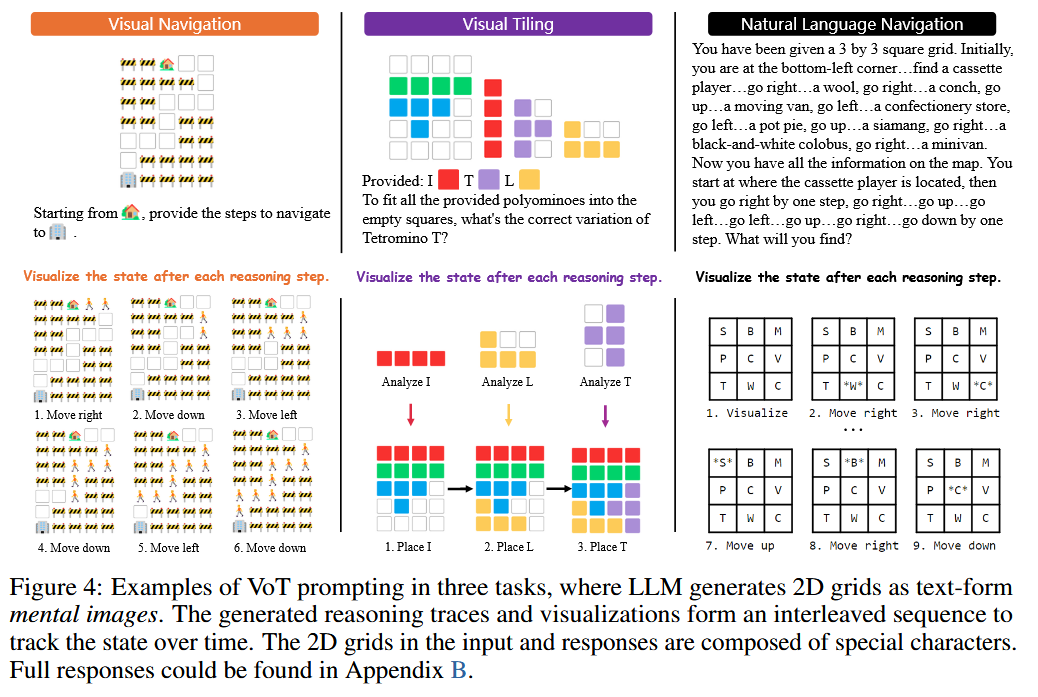
人类在导航等任务中处理空间信息的方式,诸如创建地图之类的心理图像以增强空间意识或模拟运动来告知决策是很常见的。现目标则是激发LLM的空间意识,并通过可视化其中间推理步骤的结果来为其推理提供基础。
文章重点,即介绍了Visualization-of-Thought(VoT):“Visualize the state after each reasoning step.”
VoT在三个任务中的应用:
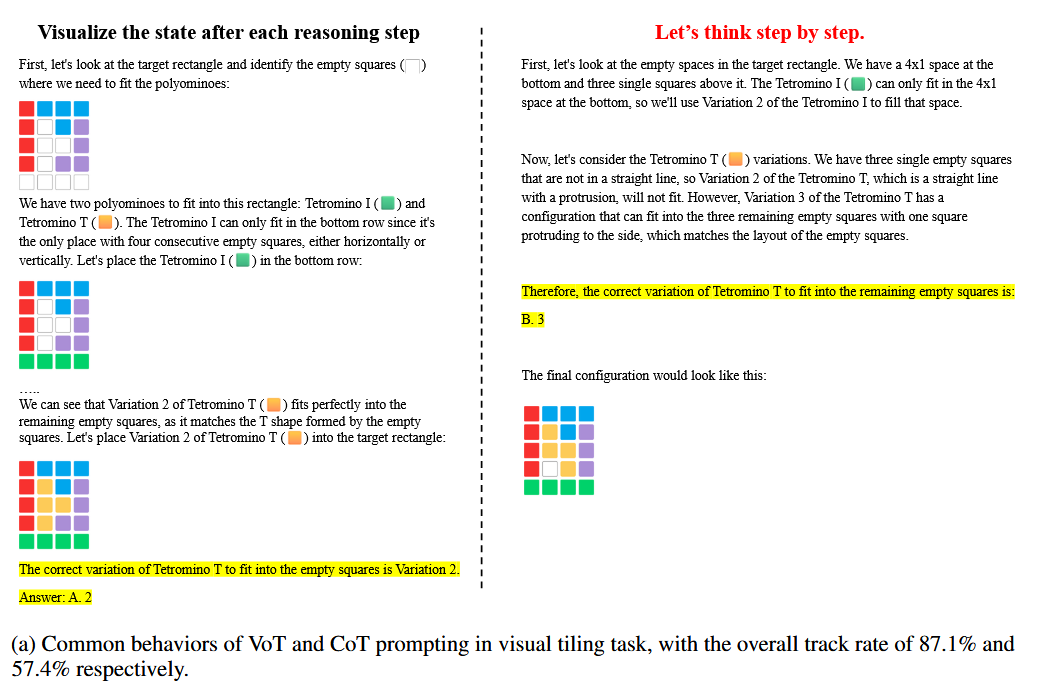
VoT和CoT的比较:
实验
实验设置
模型
- GPT-4 CoT: Let’s think step by step.
- GPT-4 w/o Viz: Don’t use visualization. Let’s think step by step.
- GPT-4V CoT: Let’s think step by step.
- GPT-4 VoT: Visualize the state after each reasoning step.
数据集
- 自然语言导航:生成了大小为3×3的200个正方形地图,这些地图由蛇形顺序遍历中的9个地标描述,并且还有一组导航指令。
- 视觉导航:生成了496张导航地图和2520个QA实例,涵盖了各种地图尺寸,最大为7×9和9×7。
- 视觉拼图:生成多个独特的配置,以填充一个包含两个I型四宫格、两个T型四宫格和一个L型四宫格的5×4矩形。之后随机遮盖了两种或三种不同类型的部件,并为每个被遮盖的部件生成QA实例,总共产生了796个QA实例。
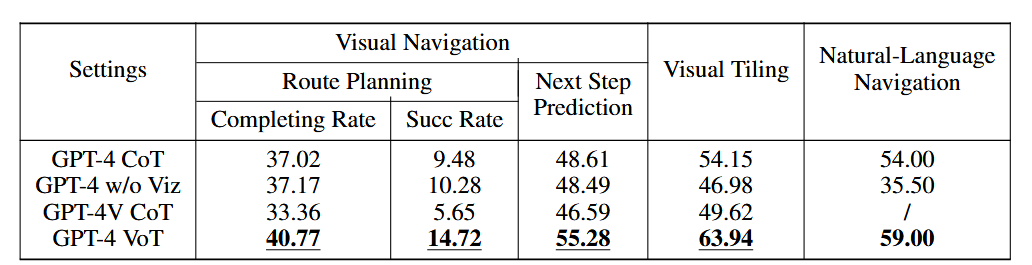
实验结果
如表所示,GPT-4 VoT 在所有指标的所有任务中都明显优于其他设置。将 GPT-4 VoT 与 GPT-4V CoT 和 GPT-4 w/o Viz 进行比较时,存在显着差距,这表明了视觉状态跟踪的有效性,它允许 LLM 直观地解释他们在接地世界中的行为。
在自然语言导航任务中,GPT-4 VoT 比 GPT-4 (不带可视化)高出 27%。在视觉任务中,GPT-4 CoT 和 GPT-4V CoT 之间的明显性能差距表明,在具有挑战性的空间推理任务中,以 2D 网格为基础的 LLM 可能优于 MLLM。
另一方面,GPT-4 VoT 在所有任务中的性能仍远非完美,尤其是在最具挑战性的路线规划任务中。尽管这些任务对人类来说相对容易,但随着任务复杂性的增加,LLM 的性能会显著下降。
分析
不同提示方法下的视觉状态跟踪行为是否有所不同?
作者通过分析模型输出中的可视化序列与推理步骤的关系,发现GPT-4在CoT提示下已经表现出一定的视觉状态跟踪能力,尤其是在需要时空模拟的任务中。然而,这种能力对提示非常敏感。VoT提示明确要求模型在推理过程中生成可视化内容,从而显著提高了视觉跟踪率,进而增强了模型的整体性能。例如,在视觉导航和拼图任务中,GPT-4 VoT的完整跟踪率和部分跟踪率均显著高于其他设置。这表明明确的可视化提示可以有效引导LLMs进行更连贯的视觉状态跟踪。
可视化如何增强最终答案的准确性?
VoT方法的核心在于通过可视化中间推理步骤来增强模型的空间推理能力。作者评估了LLMs在视觉导航和视觉拼图任务中的空间可视化能力和空间理解能力。结果显示,尽管LLMs在生成符合空间约束的可视化方面表现出潜力(合规率达到51%-52%),但其状态可视化的准确性较低(约24%-26%)。然而,当模型能够准确生成内部状态的可视化时,其在65%-77%的情况下能够做出正确决策。这表明,尽管可视化能力仍有待提高,但准确的可视化确实能够显著增强模型的推理能力。
此外,还发现在某些任务中,LLMs可以通过逻辑推理而非可视化来解决问题,这表明VoT方法在某些场景下的适用性可能受到限制。
VoT方法是否能对较小的语言模型产生效益?
为了评估VoT方法的普适性,作者在不同规模的模型(如GPT-3.5和LLAMA3系列)上进行了实验。结果表明,VoT方法在较大模型(如LLAMA3-70B)上表现出显著的性能提升,但在较小模型(如GPT-3.5和LLAMA3-8B)上效果有限。较小模型在复杂任务中更容易依赖随机猜测,导致性能波动较大。这表明VoT方法更适合于具有较强推理能力的大型模型,而对于较小模型,其效益可能受到模型基础能力的限制。
限制
· 此外,当前的可视化能力主要局限于2D网格,而更复杂的空间结构(如3D语义或复杂几何形状)尚未得到充分探索。由于LLMs的可视化能力是通过预训练中隐含的编码能力(如ASCI)获得的,因此其对提示的敏感性较高。例如,当明确提示使用ASCII时,模型的跟踪率和性能显著提升,而移除“推理”相关词汇则会导致跟踪率下降。

总结
这篇论文提出了Visualization-of-Thought(VoT)方法,旨在通过可视化中间推理步骤来提升LLM的空间推理能力。研究设计了自然语言导航、视觉导航和视觉拼图三项任务进行实验。结果表明,VoT方法显著增强了LLMs的空间推理性能,甚至超越了现有的多模态模型。
并且进一步探讨了VoT对模型视觉状态跟踪和空间理解能力的影响,发现其对大型模型效果显著,但对较小模型提升有限,且对提示敏感。论文指出,尽管VoT在2D任务中表现出潜力,但其在更复杂的空间结构和3D语义中的应用仍需进一步探索。

