
[论文学习]视觉语言大模型幻觉综述
资料
论文:[2402.00253] A Survey on Hallucination in Large Vision-Language Models
简介
本文是一篇关于LVLMs中幻觉现象的综述研究,探讨了LVLMs在视觉与语言任务中生成与事实不符内容的“幻觉”问题。文章定义了LVLMs中幻觉的概念,即指的是视觉输入(事实)与LVLM文本输出之间的矛盾。并且幻觉症状可以从认知和视觉语义的角度进行分类,包括对象、属性和关系的错误。
接着,文章介绍了评估LVLMs幻觉的方法和基准测试,包括非幻觉内容生成评估与幻觉辨别能力评估。
之后进一步分析了幻觉产生的多方面原因,包括数据偏差、视觉编码器的局限性、模态对齐问题以及LLMs自身的特性。
并且针对这些原因,其详细讨论了多种缓解幻觉的方法,如优化训练数据、增强视觉编码器能力、改进模态对齐模块以及采用后处理技术等。
最后,文章提出了未来研究方向,包括细化监督目标、多模态融合、将LVLMs作为代理以及深入研究模型的可解释性,为LVLMs的未来发展提供指导。
“幻觉”现象
LVLMs
首先了解一下LVLMs,它是一种先进的多模态模型,用来处理视觉和文本数据以解决涉及视觉和自然语言的复合任务。LVLM 模型通常由三个组件组成:视觉编码器、模态连接模块和语言模型。
- 视觉编码器通常是 CLIP 视觉编码器的改编版,它将输入图像转换为视觉标记。
- 连接模块旨在对齐视觉标记与语言模型的词嵌入空间,确保语言模型能够处理视觉信息。有多种方法可以实现模态对齐,包括跨注意力机制、适配器、Q-Former以及更简单的结构,如线性层或多层感知机(MLP)。
- 在 LVLM 中,语言模型充当中央处理器,接收对齐的视觉和文本信息,并随后合成这些信息以生成响应。
预训练阶段包括两个关键步骤,跟llm差不多:(1) 预训练,其中 LVM 从对齐的图像文本对中获得视觉语言知识; (2) 指令微调,在此期间,LVM 学习使用各种任务数据集来遵循人类指令。在这些阶段之后,LVM 可以有效地处理和解释视觉和文本数据,使它们能够推理出复合多模态任务中的概念,例如视觉问答(VQA)。
LVLMs中的幻觉

在视觉语言模型中,幻觉是指视觉输入与视觉语言模型的文本输出之间的矛盾。通过视觉任务的视角来看,视觉语言模型的幻觉症状可以被解释为判断或描述上的缺陷。如图为LVLMs”幻觉“现象的一个例子。
- 当模型对用户查询或语句的响应与实际视觉数据不一致时,就会发生判断错觉。
- 另一方面,描述错觉是指未能准确描绘视觉信息。
- 从语义的角度来看,这种不匹配可以被描述为不存在的对象、错误的对象属性或不准确的对象关系。
LVLMs“幻觉”评估与基准
评估方法和基准
根据描述和判断任务中提到的“幻觉”现象,当前的评估方法可以分为两大类,如下图所示:
(1) 评估模型生成非幻听内容的能力;
(2) 评估模型识别幻听内容的能力
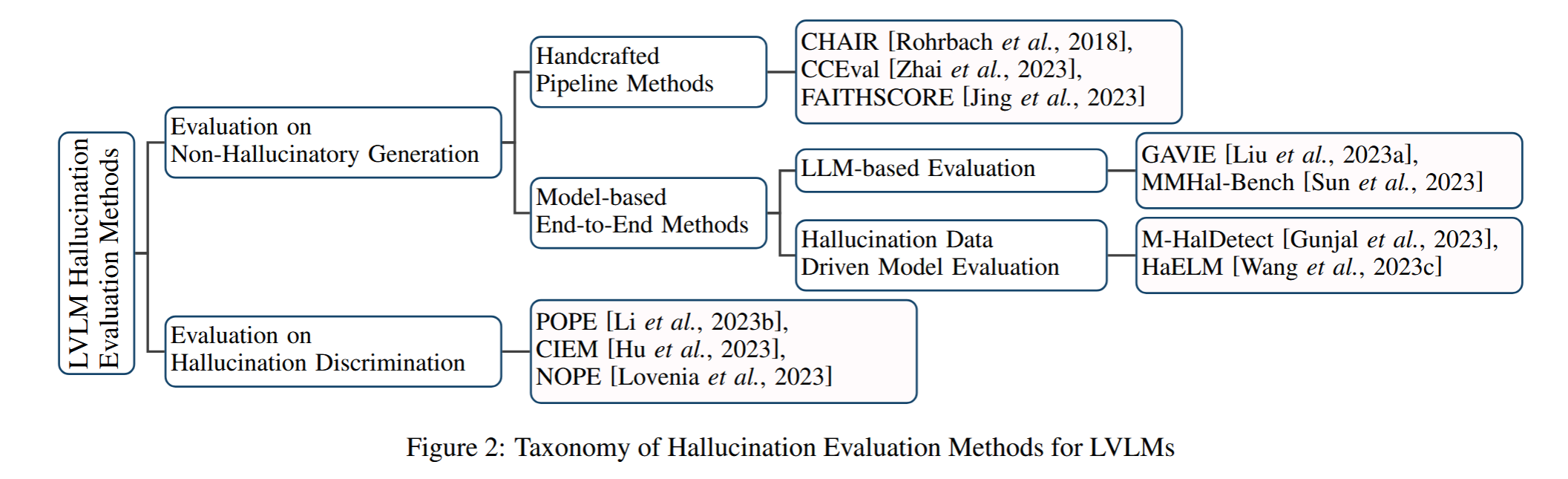
并且类似地,基于评估任务,基准也可以分为分类和生成两类,如下表所示:
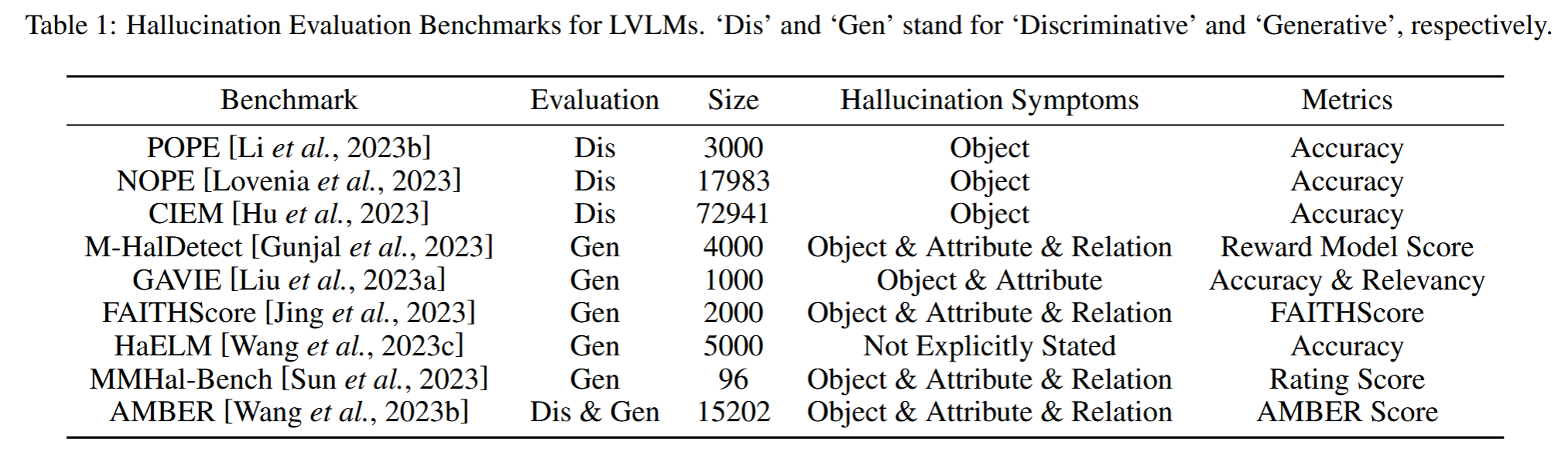
评估方法
非幻觉内容生成评估
- 手工流程方法:这些方法通过手动设计多个步骤,具有强解释性。例如,CHAIR专注于评估图像描述中对象幻觉,通过量化模型生成与真实描述之间的差异。CCEval则在应用CHAIR之前使用GPT-4进行对象对齐。FAITHSCORE提供了一种无参考的、细粒度的评估方法,通过识别描述性子句、提取原子事实,并与输入图像进行比较。
- 基于模型的端到端方法:这些方法直接评估LVLMs的响应。LLM-based Evaluation使用先进的LLM(如GPT-4)基于幻觉来评估LVLM生成的内容。幻觉数据驱动模型评估则构建标记的幻觉数据集,用于微调模型以检测幻觉。例如,M-HalDetect创建了一个带有注释的LVLM图像描述数据集,并在该数据集上微调InstructBLIP模型以识别幻觉。
幻觉鉴别评估
- 这些方法通常采用问答格式,询问LVLMs关于图像内容的问题,并评估模型的响应。例如,POPE设计了关于图像中对象存在的二元(是/否)问题来评估LVLMs的幻觉鉴别能力。CIEM类似于POPE,但通过ChatGPT自动化对象选择。NOP是另一种基于VQA的方法,旨在评估LVLMs识别视觉查询中对象缺失的能力。
基准
判别性基准
- 这些基准专注于评估模型在对象幻觉方面的性能。例如,POPE、NOPE和CIEM都是判别性基准,它们的数据集大小分别为3000、17983和72941,主要关注对象幻觉,使用准确度作为评估指标
生成性基准
- 生成性基准扩展了评估范围,包括属性和关系幻觉。例如,AMBER是一个综合性基准,集成了生成性和判别性任务。生成性基准的评估指标通常比判别性基准更复杂和多样化,因为它们需要针对特定的幻觉类别设计定制的评估方法。
VLMs“幻觉”产生原因
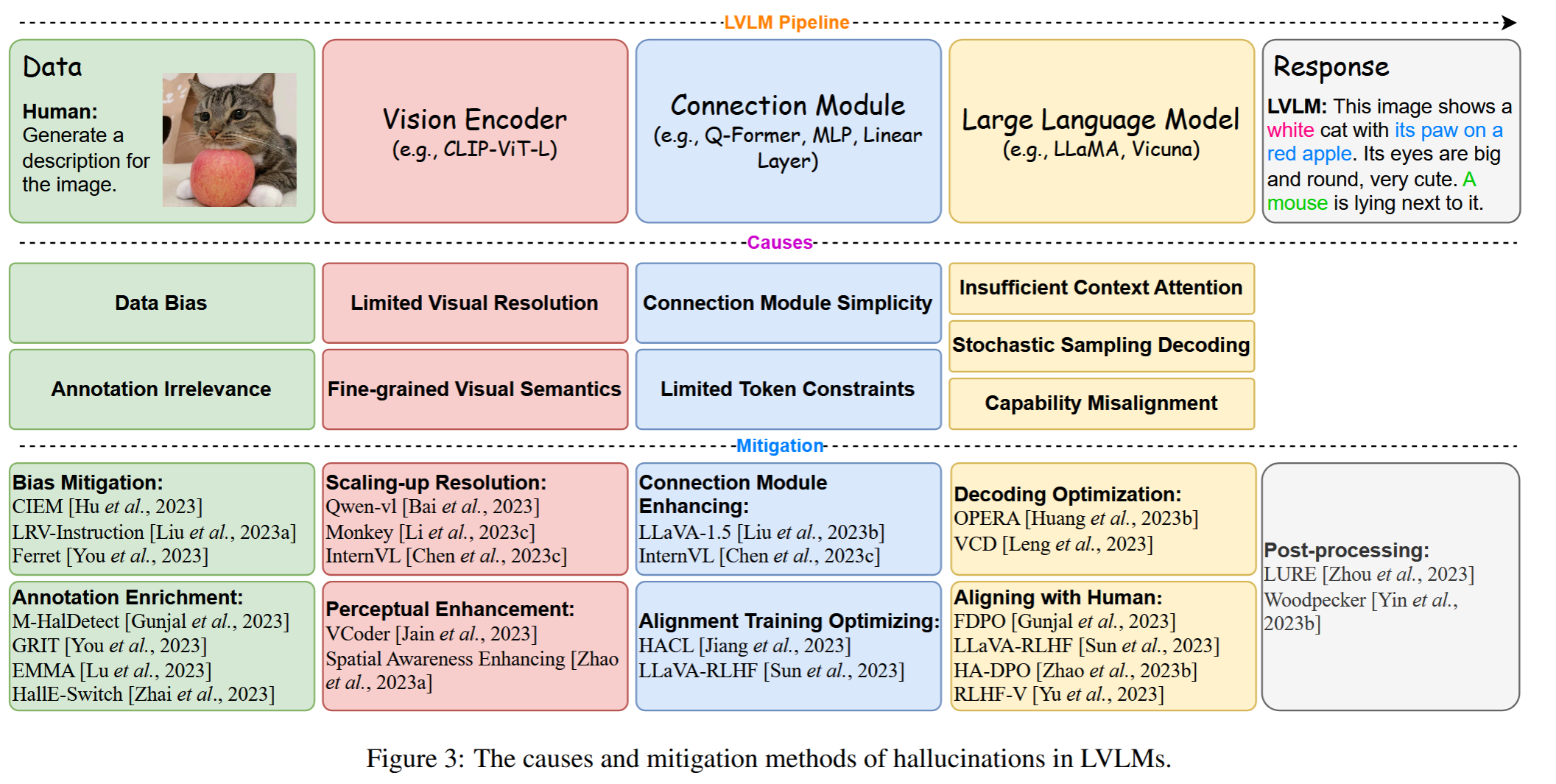
如图所示。一共有四大原因:
数据问题
- 数据偏见:训练数据中可能存在分布不平衡,例如在事实判断问答对中,大多数答案可能是“是”,导致模型倾向于给出肯定的回答,即使在不准确的情况下。
- 注释不相关性:生成的指令数据可能包含与图像内容不匹配的对象、属性和关系,这可能是由于生成模型的不可靠性造成的。
视觉编码器问题
- 有限的视觉分辨率:视觉编码器可能无法准确识别和理解高分辨率图像中的所有细节,这可能导致在生成描述时出现幻觉。
- 细粒度视觉语义:视觉编码器可能无法捕捉到图像中的所有细粒度信息,如背景描述、对象计数和对象关系,从而导致幻觉。
模态对齐问题
- 连接模块的简单性:简单的连接模块,如线性层,可能无法充分对齐视觉和文本模态,增加了幻觉的风险。
- 有限的标记约束:在模态对齐过程中,由于标记数量的限制,可能无法完全编码图像中的所有信息,导致信息丢失和幻觉。
LLM问题
- 上下文注意力不足:在解码过程中,模型可能只关注部分上下文信息,忽视了输入的视觉信息,导致生成的文本内容与视觉输入不一致。
- 随机采样解码:随机采样引入了解码过程中的随机性,虽然有助于生成多样化的内容,但也增加了幻觉的风险。
- 能力错位(Capability Misalignment):LLM在预训练阶段建立的能力与在指令调整阶段提出的扩展要求之间存在差距,导致模型生成超出其知识范围的内容,增加了幻觉的可能性。
缓解“幻觉”方法
- 数据优化:通过改进训练数据来减轻幻觉。
- 视觉编码器增强(Vision Encoder Enhancement):提高图像分辨率和感知能力。
- 连接模块增强(Connection Module Enhancement):开发更强大的连接模块以更好地对齐视觉和语言模态。
- LLM解码优化(LLM Decoding Optimization):通过优化解码策略和与人类偏好对齐来减少幻觉。
- 后处理(Post-processing):通过额外的模块或操作来修正生成的输出。
总结
本文综述了大型视觉-语言模型(LVLMs)中的幻觉问题,LVLMs在开放域视觉-语言任务中表现出色,但幻觉问题仍然是一个挑战。本文为解决LVLMs中的幻觉问题奠定了基础,并为未来研究提供了方向。
