
[论文学习]大型多模态模型空间推理能力的实证分析
资料
论文:[2411.06048] An Empirical Analysis on Spatial Reasoning Capabilities of Large Multimodal Modelshttps://arxiv.org/abs/2402.00253)
简介
本文旨在深入研究大型多模态模型(LMMs)的空间推理能力。作者构建了一个新的视觉问答(VQA)数据集 Spatial-MM,包含两个子集:Spatial-Obj 和 Spatial-CoT,分别用于评估 LMMs 对图像中物体空间关系的理解以及多跳推理能力。
研究发现,边界框和场景图(尤其是合成的场景图)能够显著提升 LMMs 的空间推理性能,但在处理从人类视角提出的问题时,LMMs 的表现明显不如从相机视角。此外,传统的链式推理CoT提示在多跳空间推理任务中效果有限,而场景图在多跳推理中更为有效。通过扰动分析,作者还发现 LMMs 在基本物体检测任务中表现较强,但在复杂空间关系理解方面存在明显不足。这些发现揭示了当前 LMMs 在空间推理方面的局限性,并为未来多模态模型的研究和开发提供了重要参考。
Spatial-MM基准测试
用于研究人类和LMM之间的空间推理能力差距。基于观察到现有的基准仅部分调查了LMM的空间推理能力,引入了一个新的基准,Spatial-MM,它包括两个子集:Spatial-Obj和Spatial-CoT。Spatial-Obj具有多项选择题,专注于图像中一个或两个对象之间的空间关系,而Spatial-CoT则提供开放式多跳问题。
Spatial-Obj
Spatial-Obj是一个精心策划的基准,包含2000个多项选择题,旨在评估LMM在给定图像中对一个或两个对象的空间推理能力。
数据集由两轮注释构成。在第一轮注释中,我们将图像分成三个注释者,并要求他们在每张图像中选择一个或两个对象,并组成一个问答 (QA)。对,包括空间关系。为注释者提供了带有ob-jects占位符的问题模板,他们可以根据自己的喜好使用或进行自定义。在第二轮注释中,我们发布了200QA对的批次及其相应图像。另外10个注释者的任务是审查这些QA对,以验证它们是否正确或不正确/不明确。根据他们的反馈进行了更正。
这个数据集涵盖了36个最常用的空间关系,包括右、左、附着、触摸、后、下、前、后,朝下,朝外,顶部,下面,旁边,后面,下面,上,里,正面、下方、上方、中间、内部、外部、右下角、左下角、右上方、左上方、角落、靠近、旁边、靠近。此外,我们使用GPT-4o将空间对象分类为视觉模式,例如 “对象定位” 、 “方向和方向” 、 “视点” 和 “位置和关系上下文”。

Spatial-CoT
Cot已被证明可以显著提高LLMs的推理能力。然而,最近的研究表明,在通过CoT提示回答问题时存在不一致性。也就是说,在使用CoT生成推理路径时,LLM可以产生正确的答案,但生成的推理路径并不总是正确的。这种差异是一种幻觉形式,并使LLMs的推理变得不可靠。
为了研究lmm在Cot下的空间推理的可信度,我们策划了一个多跳问答对数据集Spatial-CoT。QA对是通过提示GPT-4o给定图像和一组上下文相关的示例生成的。总共生成了800个多跳QA对,我们筛选出了178个不包括上一节中列出的36个空间关系中的至少一个的QA对。然后人来选择合理且有意义的多跳QA对,这些QA对至少需要两个推理步骤才能达到最终答案。最终,空间CoT包括310个空间感知的多跳QA对。
在知识图谱问题回答中,三元组被认为是推理步骤。利用这个想法,在VQA任务中,我们利用场景图,包括对象关系或属性,作为导致答案的推理步骤。重要的是要注意当前的VQA基准测试使用地面真实场景图,缺乏多样化的视角信息,只从相机的角度考虑空间关系。对于空间Cot,由于不存在真实路径 (或场景图),为了评估LMMs的空间推理能力,我们为每个问题生成推理路径。通过一组上下文相关的例子仔细地指导GPT-4o生成空间感知推理路径的初稿。随后,三名调查员被指派进行评估 (即保留、删除、添加或修改) 每个问题的生成步骤。空间跳跃的步骤标记为S,例如 “车前的人”,非空间跳跃的步骤标记为S,例如 “拿叉子的女人”。

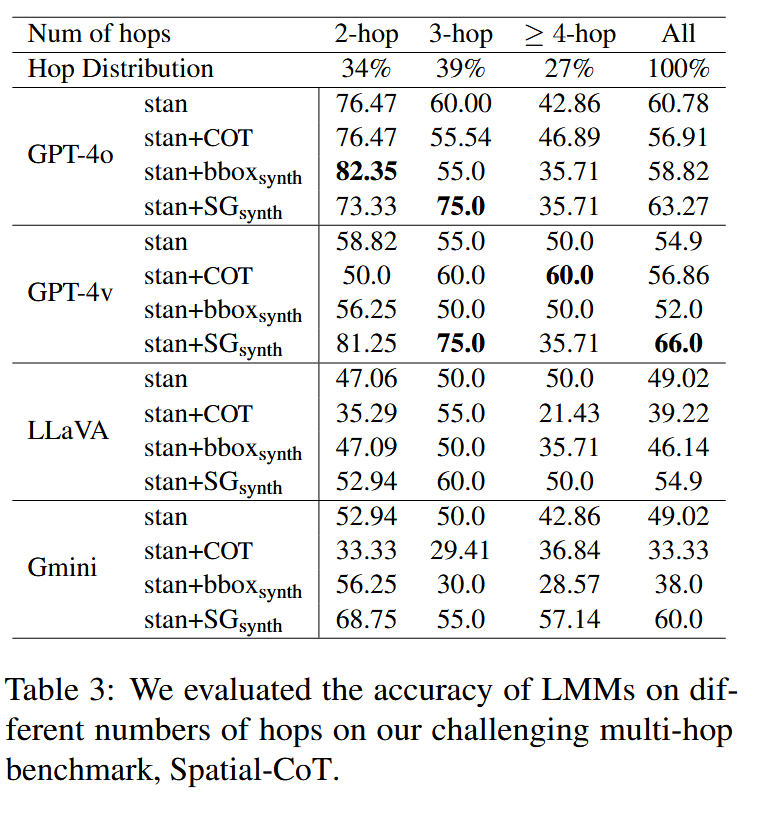
每个推理路径包括两个或多个跳,至少有一个是空间跳跃。如上图显示了一些具有相应推理路径的多跳QA示例。如下表所示,在问题中,34%的问题有两个跳的推理路径,39%有三个跳,27%需要四个或更多个跳来回答。
丰富数据以提高空间推理能力
直观地说,为LMMs提供额外的空间感知视觉基础数据将有助于提高他们的空间推理性能。
为了测试这一假设,我们描述了两个生成不同类型的可视化地面数据的管道。
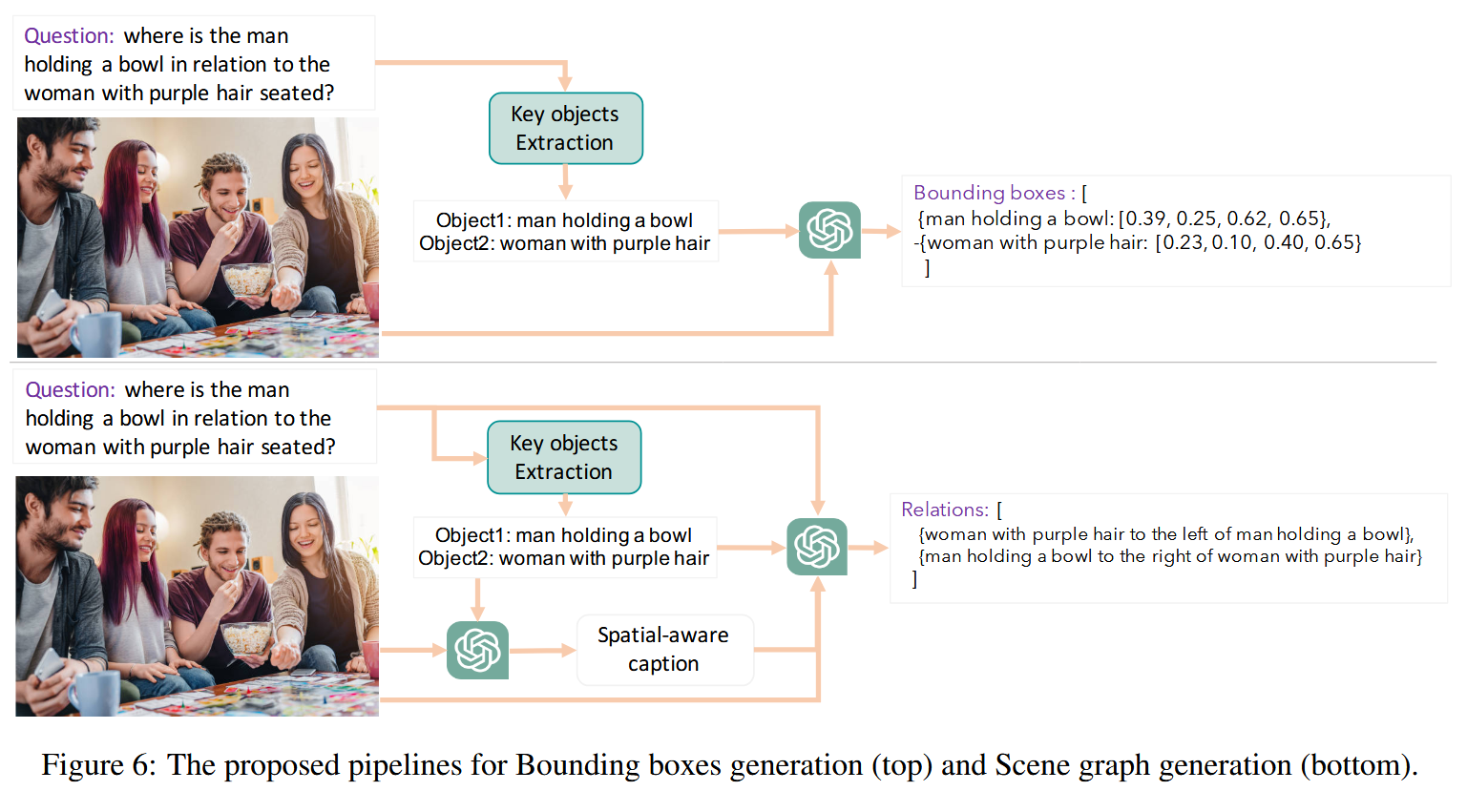
第一个管道包括两个阶段 : (I) 关键对象提取和 (II) 边界框生成。
第二个管道包括三个阶段 : (I) 关键物体提取,(II) 与关键物体相关的空间感知捕获生成,以及 (III) 空间感知的场景图生成。
此外,我们描述推理多跳问题的路径生成。
边界框生成。管道的输入是我与多项选择题Q配对的图像。我们首先从给定的问题中提取关键的对象 [$object1$,$object_2$,..]。接下来,我们提示GPT-4o提供图像中关键对象的绑定框。每个边界框具体表示为一个元组 [$x{min}$,$y{min}$,$x{max}$,$y{max}$],其中$x{min}$和$y{min}$是左上角的坐标,$x{max}$和$y_{max}$是右下角的坐标。
场景图生成。类似于边界框生成的第一阶段,我们从给定的问题中提取关键对象。然后,我们会提示GPT-4o通过考虑图像中关键物体的位置、方向和空间关系来生成空间感知标题。最后,针对空间感知标题、关键对象和图像,提示GPT-4o提取图像中关键对象的空间关系、方向和方向。

推理路径生成。之前关于评估LMMs的研究只关注最终答案的准确性,而忽略了生成的推理路径的正确性。在这项工作中,我们通过利用为多跳问题生成的真实推理步骤,深入研究了多跳VQA中LMMs的空间推理路径。为了应对评估非结构化推理步骤的挑战,我们仔细设计了一个提示策略,指示LMMs以场景图格式输出推理步骤。这使我们能够验证地面真理推理步骤。
实验
主要围绕新构建的Spatial-MM数据集以及GQA-spatial数据集展开。实验涉及多个方面,包括边界框和场景图对模型性能的影响、视角(人类视角与相机视角)对推理能力的影响,以及多跳推理任务中的模型表现。
实验设置
数据集
实验使用了以下两个数据集:
- Spatial-MM:包含两个子集:
- Spatial-Obj:2000个多项选择题,评估LMMs对图像中一个或两个物体的空间关系理解。
- Spatial-CoT:310个多跳推理问题,评估模型在空间关系上的链式推理能力。
- GQA-spatial:基于GQA数据集,包含从相机视角提出的关于物体空间关系的二选一问题。
模型
实验评估了以下四种顶级LMMs:LLaVA-1.5-7B、GPT-4 Vision、GPT-4o、Gemini 1.5 Pro。
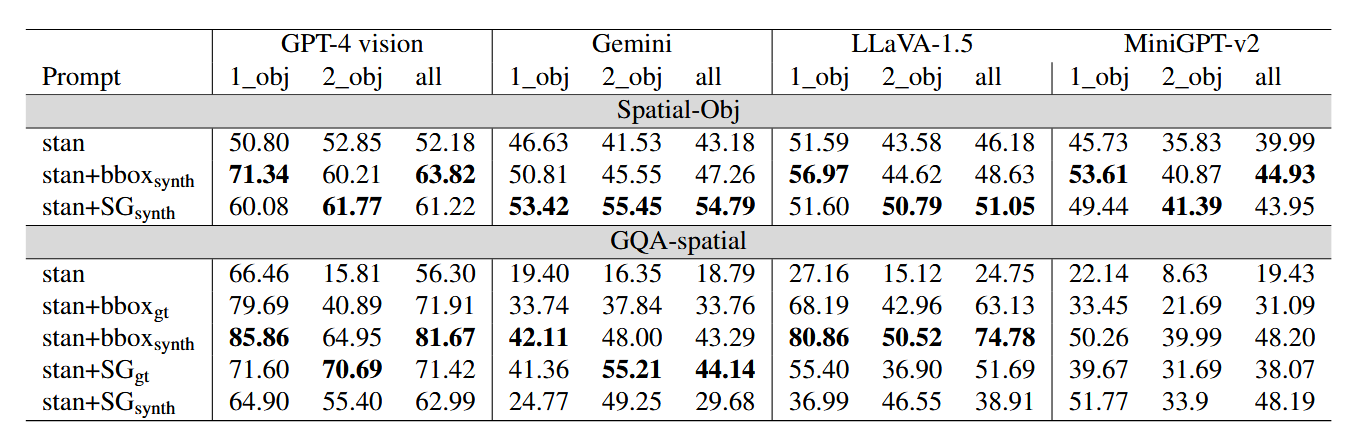
边界框和场景图的影响
为了探究边界框和场景图对空间推理的增强作用,实验设计了以下几种输入条件:
- 标准输入(Standard):仅提供图像和问题。
- 合成边界框(bboxsynth):通过GPT-4o生成关键物体的边界框。
- 合成场景图(SGsynth):通过GPT-4o生成关键物体的空间关系图。
- 真实边界框(bboxgt):使用真实标注的边界框。
- 真实场景图(SGgt):使用真实标注的场景图。
视角的影响
实验比较了模型在处理从人类视角(如图像内人物的视角)和相机视角(如图像外的观察者视角)提出的问题时的表现差异。
多跳推理分析
通过Spatial-CoT数据集,实验分析了不同推理步骤数量(如2跳、3跳、≥4跳)对模型性能的影响,并评估了链式推理(CoT)提示的有效性。
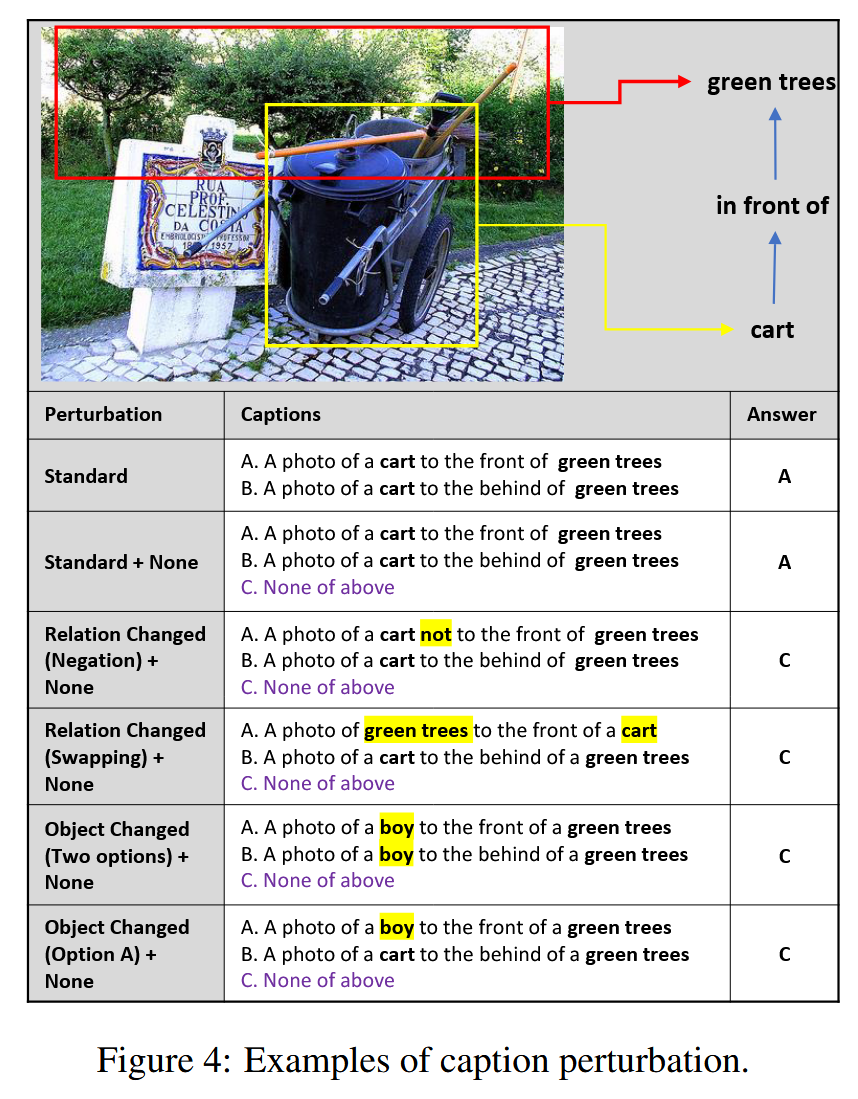
扰动分析
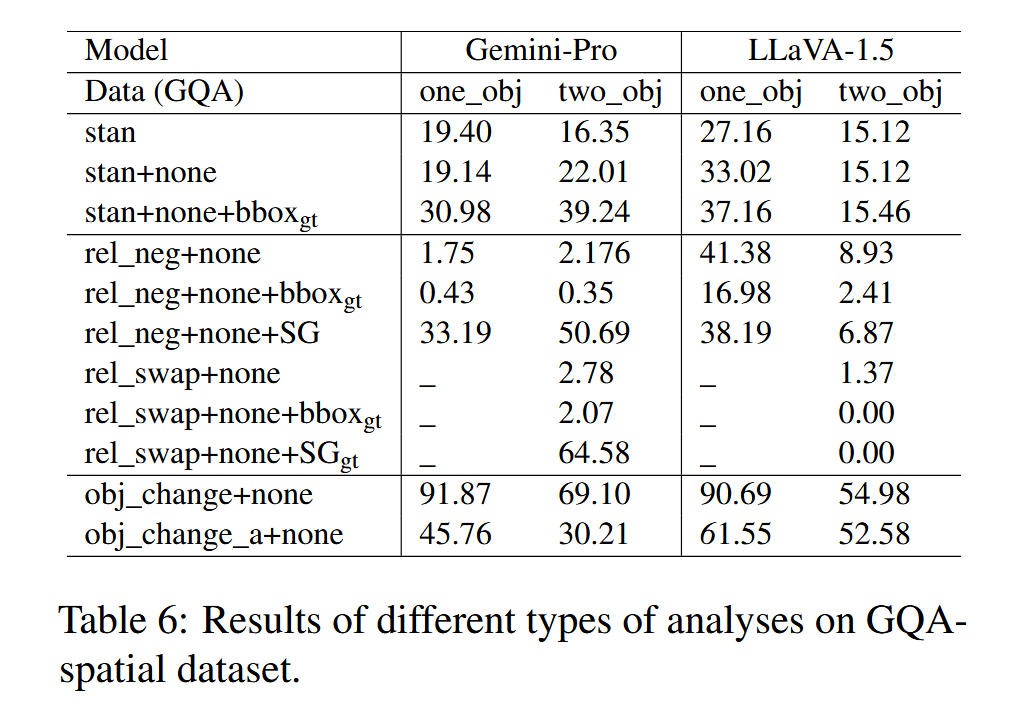
在GQA-spatial数据集上,实验通过以下五种扰动设置分析模型的鲁棒性:
- none:添加“以上皆非”选项。
- rel_neg:在正确选项中添加“not”。
- rel_swap:交换选项中的关键物体。
- obj_change:将选项中的关键物体替换为图像中不存在的物体。
- obj_change_a:仅在正确选项中替换关键物体。
实验结果
边界框和场景图的作用
- 边界框和场景图显著提升了LMMs的空间推理能力,尤其是合成场景图在多跳推理任务中效果显著。
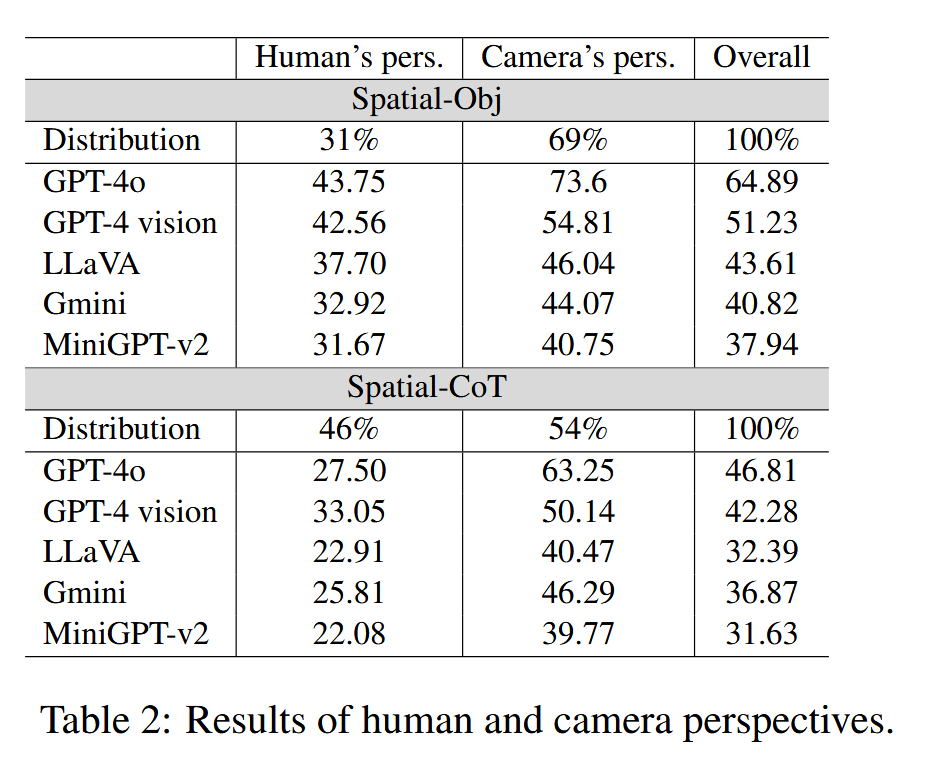
- 在Spatial-Obj数据集上,GPT-4 Vision使用合成场景图后,准确率从51.23%提升至66.0%。
- 在GQA-spatial数据集上,合成边界框使模型性能平均提升33个百分点。
视角的影响
- LMMs在处理从人类视角提出的问题时表现较差,准确率显著低于从相机视角提出的问题。
- 例如,GPT-4o在人类视角下的准确率为43.75%,而在相机视角下为73.6%。
多跳推理的挑战
- 链式推理(CoT)提示在多跳空间推理任务中效果有限,而场景图能够显著提升模型在多跳问题上的表现。
- 随着推理步骤数量的增加,模型的最终答案准确率显著下降。
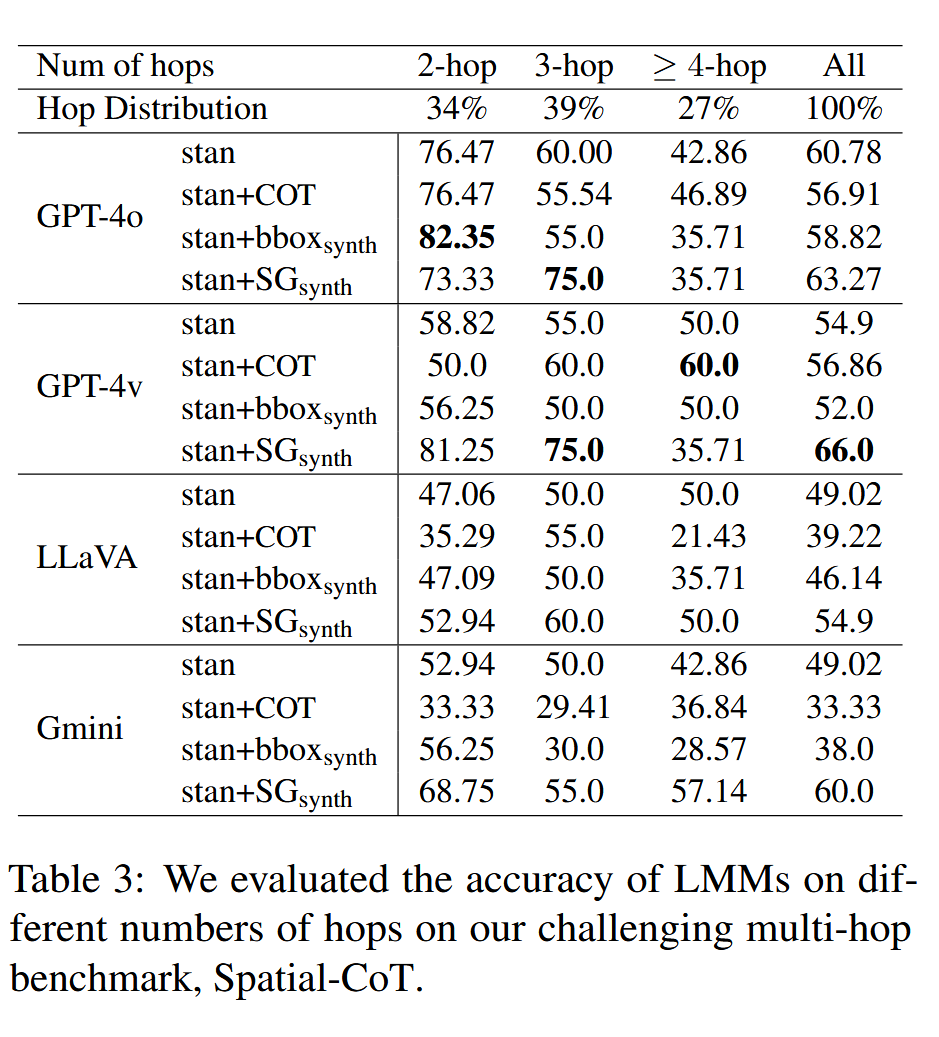
表4列出了所有空间和非空间推理步骤在Spatial-CoT问题中的平均分数,这表明空间和非空间推理步骤的F1得分之间的平均差距显著为stan上的21分和stan + SGsynth提示下的19分。、
表5给出了分析LMMs无法通过斯坦提示正确回答的问题的推理路径的结果。不正确的推理路径可能由于不正确的空间步骤、不正确的非空间步骤或两者的结合而发生。平均而言,只有1% 的问题的推理路径正确,但最终答案不正确。此外,91% 的问题包含至少一个错误的空间推理步骤,而只有9.75% 包含至少一个错误的非空间推理步骤。请注意,当推理步骤在语义上与基本事实推理步骤不匹配,或者生成的路径中缺少基本事实路径的推理步骤时,会发生不正确的推理步骤。

扰动分析
- LMMs在基本物体检测任务中表现较强,但在复杂空间关系理解方面表现较弱。
- 在扰动设置中,模型在处理“obj_change”(物体替换为不存在的物体)时表现最好,而在处理“rel_swap”(关系交换)时表现最差。
发现
| 发现一 | 提高LMM在视觉推理任务中的能力。边界框对一对象问题更有效,而场景图对两对象问题更有帮助。 |
|---|---|
| 发现二 | LMM 在从相机的角度理解场景方面表现出色。然而,当问题是从图像中的人类视角提出时,它们的表现会显著下降。 |
| 发现三 | 思维链提示对多跳空间推理无效。 |
| 发现四 | LMMs 在物体检测任务(识别图像中存在的对象)方面通常表现良好,但在空间推理(区分“左”和“右”)方面却很困难。 |
总结
在本文中,提出了一个新的基准来评估LMMs的空间推理能力,由两个子集组成: 空间对象包含2000个多项选择题,用于评估给定图像中一个或两个对象的空间推理能力。包含310个多跳问题的空间集合,用于评估空间相关的集合和推理路径。
本文表明,尽管LMMs在视觉和语言任务中表现出色,但在空间推理方面仍存在显著不足,尤其是在处理从人类视角提出的问题和复杂多跳推理任务时。边界框和场景图能够显著提升模型的空间推理能力,但链式推理提示在多跳空间推理任务中效果有限。这些发现为未来多模态模型的研究和开发提供了重要的参考方向。

