
[论文学习]VSI-Bench:多模态大型语言模型如何观察、记忆和回忆空间
资料
论文: Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
代码:vision-x-nyu/thinking-in-space: Official repo and evaluation implementation of VSI-Bench
简介
该论文探讨了MLLMs是否能够像人类一样通过视频“思考空间”,即感知、记忆和回忆环境中的空间布局。研究者们提出了一个新的视频基准测试VSI-Bench,包含超过5000个问答对,用于评估MLLMs在视觉空间智能方面的表现。研究发现,尽管MLLMs在某些任务上展现出接近人类的性能,但在空间推理能力上仍存在瓶颈,尤其是在构建全局空间模型和执行自我中心-他中心视角转换方面。此外,论文还发现,传统的语言推理技巧(如Cot、自我解释等)对提升MLLMs的空间智能效果有限,而显式生成“认知地图”可以显著增强其空间距离估计能力。这项工作为理解和改进MLLMs的空间智能提供了新的视角。
VSI-Bench设置背景
视觉空间智能
视觉空间智能是指人类通过视觉信号感知和操纵空间关系的能力。它涉及多种能力,包括关系推理、自我中心和环境中心视角之间的转换。
- 关系推理:通过距离和方向来识别物体之间关系 的能力,还包括依靠关于其他物体大小的视觉空间常识 来推断物体之间的距离。
- 自我中心和环境中心视角转换:当人类观察一个空间时,他们会将自我中心的感知转换为环境中心的心理地图, 从而能够从不同的视角进行换位思考。这种转换依赖于对新视角的 想象以及视觉空间工作记忆,即能够保持和处理空间信息的能力,例如通过新的以自我 为中心的输入来更新物体的位置。
例如,当我们购物时,我们常常试图回忆家中的客厅布局,以判断心仪的柜子是否合适。这种能力不仅对人类的日常生活至关重要,也是机器人、自动驾驶和AR/VR等领域的重要基础。然而,尽管MLLMs在语言智能方面取得了巨大进展,其视觉空间智能仍然有待探索。
VSI-Bench数据内容
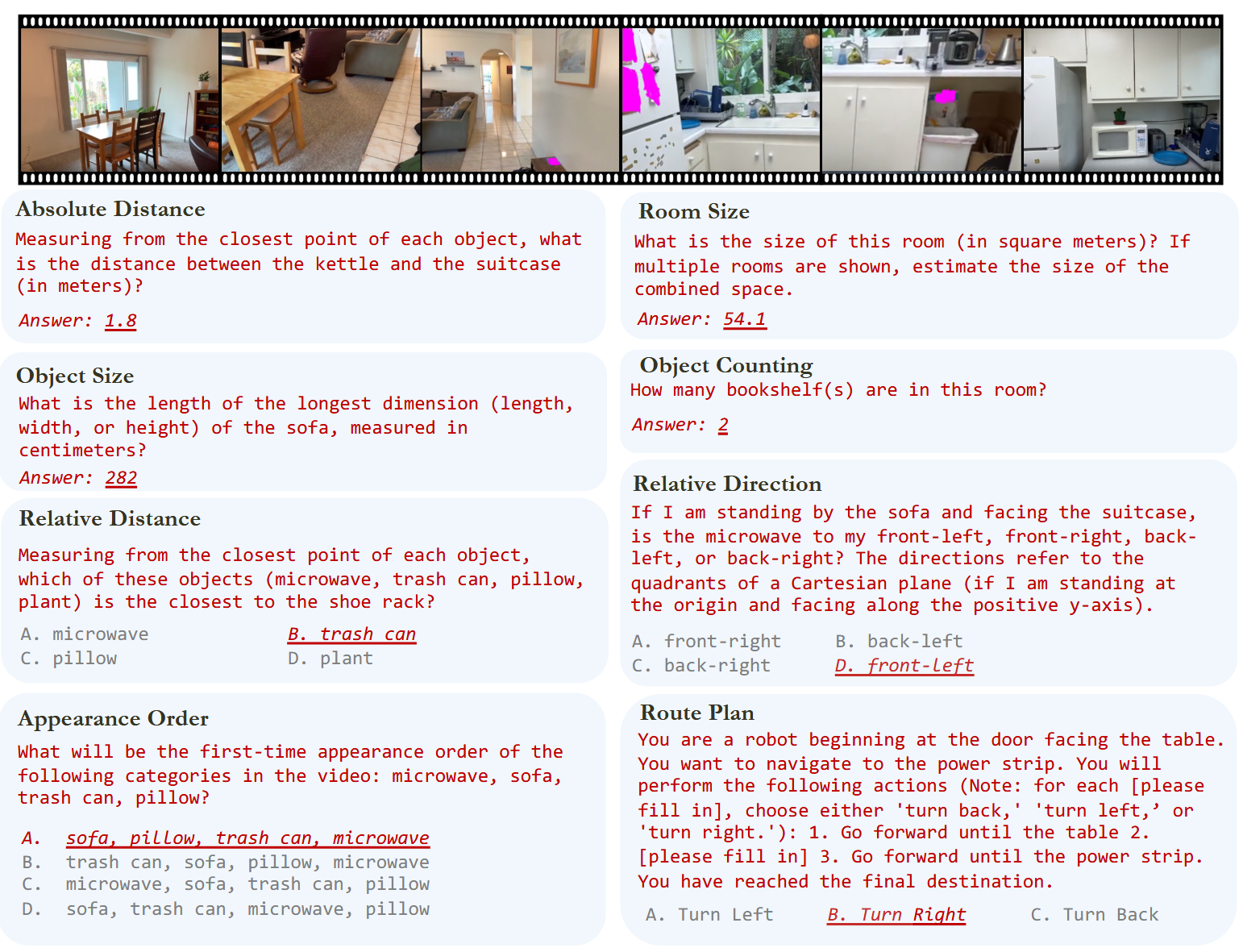
VSI-Bench是一个基于视频的视觉空间智能基准测试,包含超过5000个问答对,覆盖近290个真实室内场景视频。这些视频来自ScanNet、ScanNet++和ARKitScenes等公共室内场景重建数据集,涵盖了住宅、办公室、实验室和工厂等多种环境。
VSI-Bench的任务分为三类:配置类(如物体计数、相对距离)、测量类(如物体大小、房间大小)和时空类(如物体出现顺序)。
- 数据收集与统一:首先将各种数据集标准化为统一的元信息结构,以确保生成与数据集无关的问答对。这些数据集提供了能够进行空间重建的高保真视频扫描, 确保多模态语言模型仅通过视频输入就能回答空间层面的问题。
- 问题-答案生成:问答对主要通过元信息和问题模板自动标注;路线规划任务则由人工标注。我们为每个任务精 心设计并完善问题模板,并为人工标注员提供指导方针。
- 人工干预的质量审查:人工更新和迭代基准,直至其满足我们的质量标准。
VSI-Bench评估与结果展示
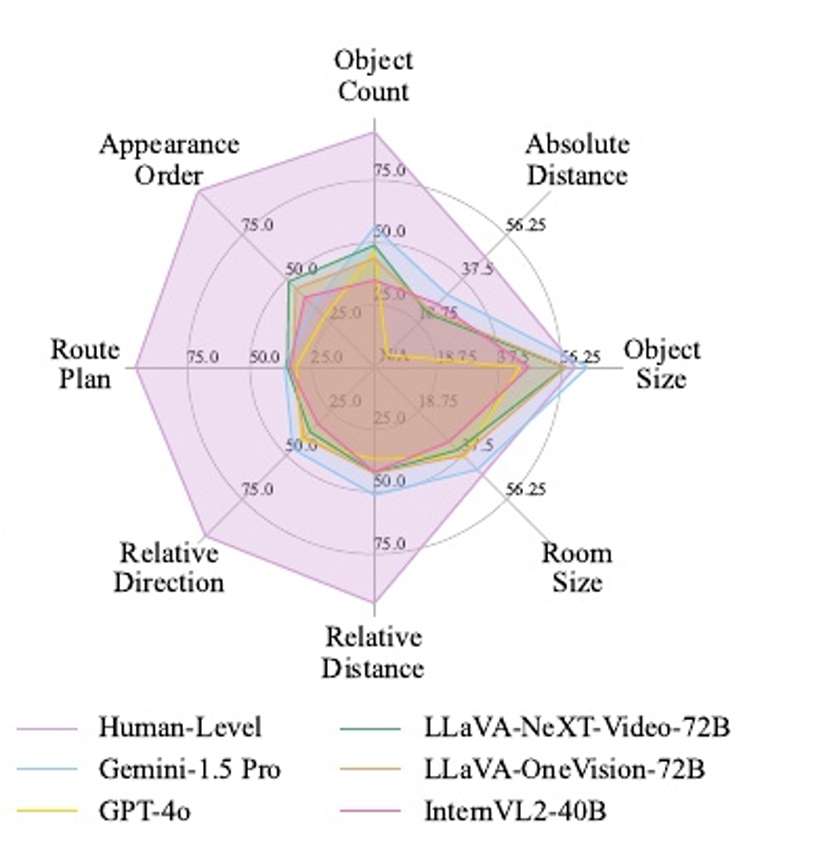
在VSI-Bench上,研究人员评估了15种不同的MLLMs,包括Gemini和GPT-4o等专有模型以及InternVL2和LLaVA-NeXT等开源模型。
其中对于度量设计,其分为多项选择题(MCA)、数值题(NA)。对于MCA问题,采用基于精确匹配的准确率作为主要度量标准。对于 NA 任务,由于模型预测的是连续值,不能采用精确匹配计算,所以引入平均相对准确率(MRA)。
结果显示,尽管MLLMs在某些任务上表现出色,但与人类水平相比仍有较大差距。例如,在物体计数和相对方向任务上,人类的准确率接近95%,而最佳模型的准确率仅为45%-68%。此外,研究还发现,MLLMs在需要精确估计的任务(如绝对距离和物体大小)上表现稍好,但在需要全局空间推理的任务(如路线规划和相对方向)上表现较差。
VSI-Bench探索提高
自我解释推理(Self-Explanations)
为了更好地理解MLLMs的空间推理过程,研究人员通过自我解释推理来分析模型的行为。他们让模型在回答问题后提供逐步解释,发现MLLMs在视频理解方面表现出色,但在空间推理方面仍存在不足。
此外,其带有时间戳的描述令人印象深刻,准确度极高。该模型还能形成正确的分步推理过程,例如在相对方向任务中, 会列出“确定自身位置”“找到洗碗机”和“想象象限”等 步骤。并且其构建全局坐标系表明,多模态大模型可能拥有或能够构建隐式的世界模型。该模型并非依靠孤立的帧、短片段或随机猜测,而是利用全局空间背景和推理来正确推断。
举一个例子,在一个相对方向的任务中,模型能够准确描述物体的位置,但在转换视角时却出现了错误。这表明,尽管MLLMs能够理解视频内容,但在构建全局空间模型时仍面临挑战(理解为自我中心和环境中心视角转换的能力不行)。

思维链(Cot)
研究人员尝试采用三种方式:Zero-Shot CoT、Cot与Self-Consistency、ToT来提升MLLMs的空间智能。发现其三种方法在VSI-Bench上反而导致了性能下降。这表明,语言提示技术虽然在语言推理和一般视觉任务中效果显著,但对空间推理却有害无益。仅仅通过语言推理技巧无法有效提升MLLMs的空间智能,空间推理需要更深层次的视觉和空间理解。
零样本Cot:

Cot与Self-Consistency:

ToT:

认知地图(Cognitive Maps)
研究人员提示MLLM使用认知地图来表达它们对所见空间的内部表征,认知地图是一种用于在特定环境中记住物体位置的成熟框架。让模型根据视频输入预测 10×10 网格中的物体中心位置,如图展示由此产生的认知地图示例。
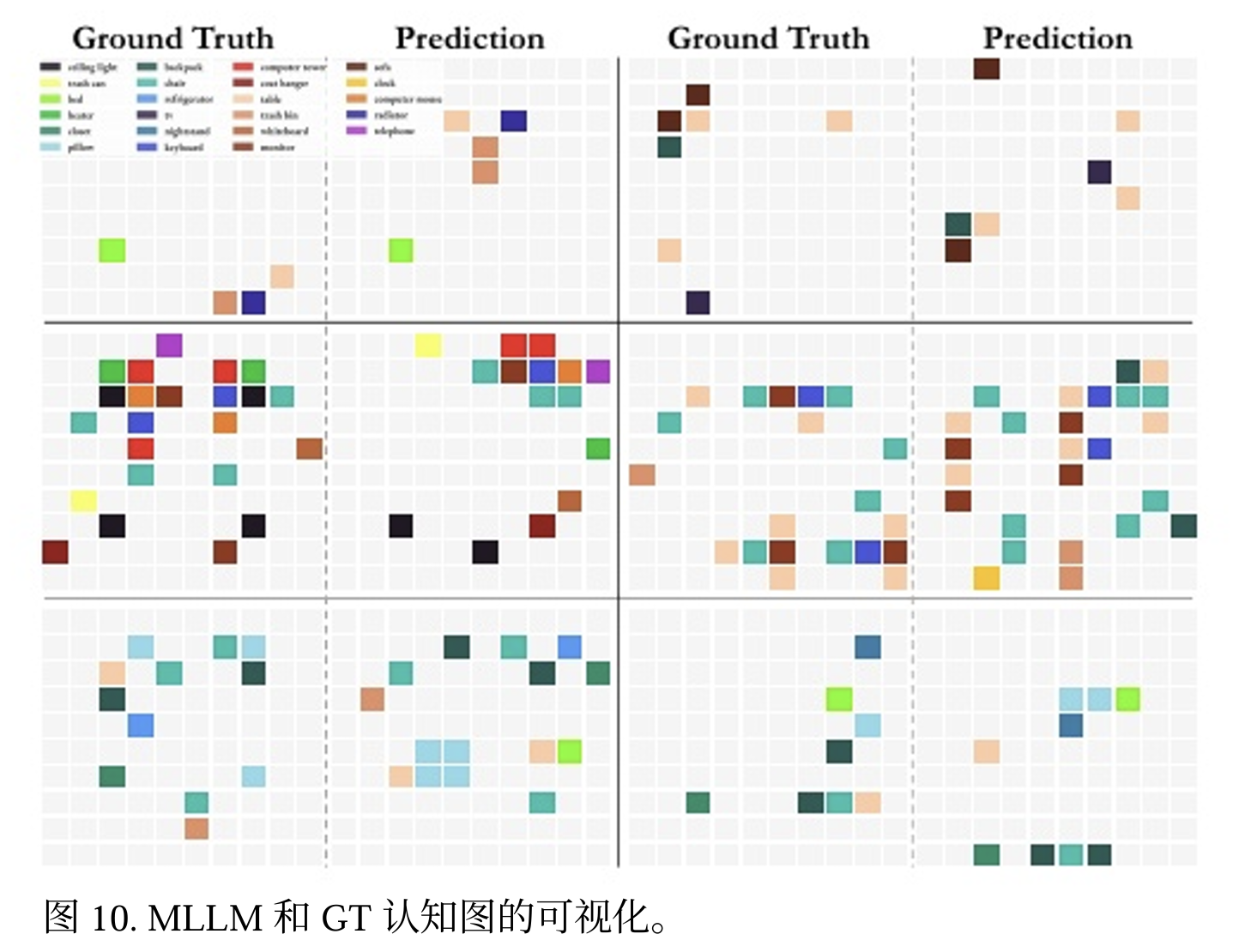
实验发现 MLLM 在其认知地图中定位相邻对象的准确率达到了很高的 64%,这表明其具有很强的局部空间感知能力。如图:
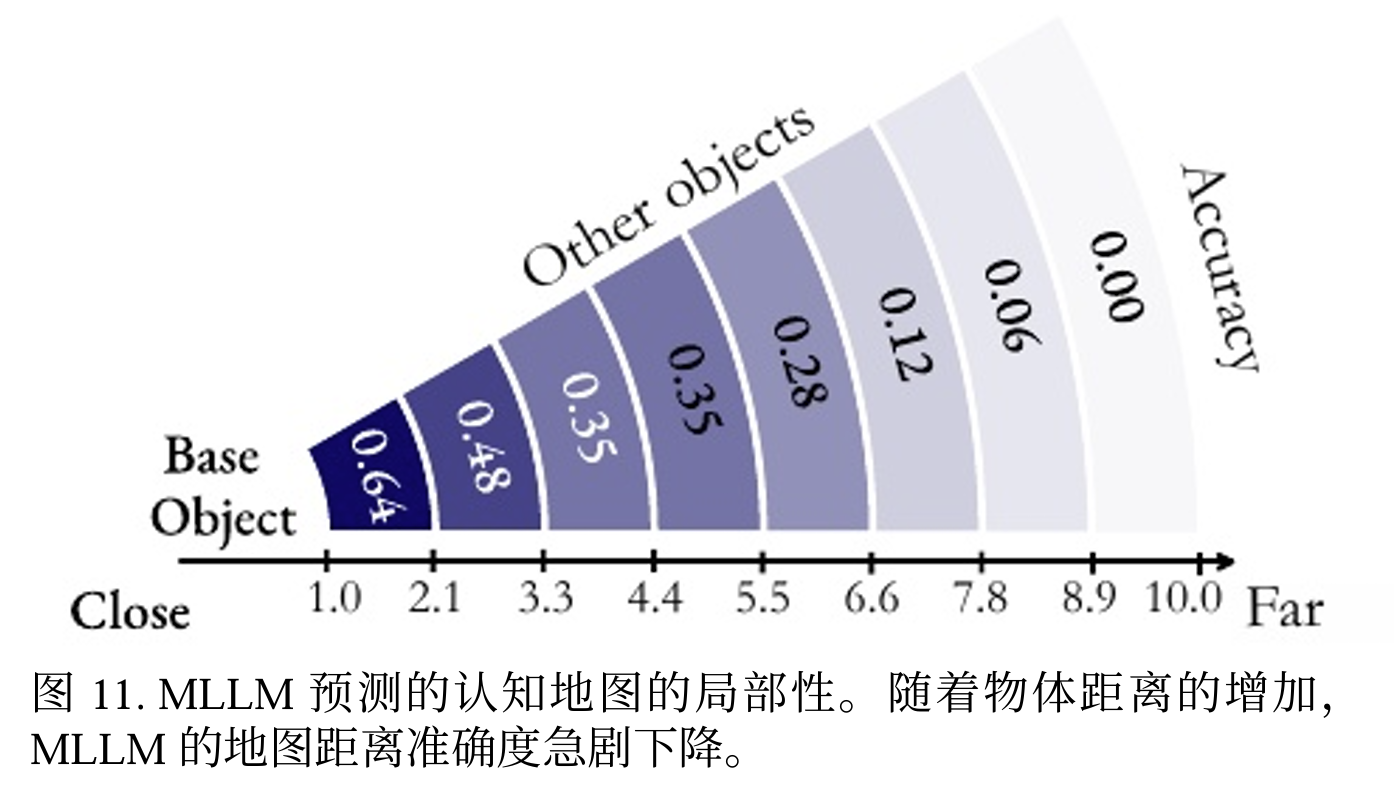
然而,随着两个对象之间距离的增加,这一准确率显著下降。这表表明,在记忆空间时,MLLM会从给定的视 频中在脑海中构建一系列局部世界模型,而非一个统一的全局模型。
其构建地图的Prompt是:
1 | 这段视频记录了一个室内场景。您的任务是识别视频中的特定物体,理解场景的空间布局,并估算每个物体的中心点,假设整个场景由一个 10×10 的网格来表示。[规则] |
其中,categories_of_interest包括如下:

通过认知地图实现更优的距离推理
研究人员尝试让模型显式生成“认知地图”,即通过视频输入预测物体的中心位置。结果显示,这种方法显著提升了模型在空间距离任务上的表现。例如,当模型使用生成的认知地图回答问题时,其相对距离任务的准确率从46%提升到56%,在使用真实认知地图的情况下准确率提高了 46% 至 66%。这表明,认知地图能够帮助MLLMs更好地理解和回忆空间布局,是提升空间智能的一个有效途径。

总结
VSI-Bench为评估和改进MLLMs的视觉空间智能提供了一个全新的视角。通过这项研究,我们不仅看到了MLLMs在视觉空间智能方面的 现有优势(例如,突出的感知、时间和语言能力)以及瓶颈(例如,自我中心-他者中心转换和关系推理)。
未来的研究可以进一步探索如何通过任务特定的微调、自监督学习目标或专门的视觉空间提示技术来提升MLLMs的空间智能。

